The MTG-Jamendo Dataset
![]()
We present the MTG-Jamendo Dataset, a new open dataset for music auto-tagging. It is built using music available at Jamendo under Creative Commons licenses and tags provided by content uploaders. The dataset contains over 55,000 full audio tracks with 195 tags from genre, instrument, and mood/theme categories. We provide elaborated data splits for researchers and report the performance of a simple baseline approach on five different sets of tags: genre, instrument, mood/theme, top-50, and overall.
This repository contains metadata, scripts, instructions on how to download and use the dataset and reproduce baseline results.
A subset of the dataset was used in the Emotion and Theme Recognition in Music Task within MediaEval 2019-2021.
Table of contents:
- Structure
- Using the dataset
- Related Datasets
- Research challenges using the dataset
- Citing the dataset
- License
- Acknowledgments
Structure
Metadata files in data
Pre-processing
raw.tsv(56,639) - raw file without postprocessingraw_30s.tsv(55,701) - tracks with duration more than 30sraw_30s_cleantags.tsv(55,701) - with tags merged according totag_map.jsonraw_30s_cleantags_50artists.tsv(55,609) - with tags that have at least 50 unique artiststag_map.json- map of tags that we mergedtags_top50.txt- list of top 50 tagsautotagging.tsv=raw_30sec_cleantags_50artists.tsv- base file for autotagging (after all postprocessing, 195 tags)
Subsets
autotagging_top50tags.tsv(54,380) - only top 50 tags according to tag frequency in terms of tracksautotagging_genre.tsv(55,215) - only tracks with genre tags (95 tags), and only those tagsautotagging_instrument.tsv(25,135) - instrument tags (41 tags)autotagging_moodtheme.tsv(18,486) - mood/theme tags (59 tags)
Splits
splitsfolder contains training/validation/testing sets forautotagging.tsvand subsets
Note: A few tags are discarded in the splits to guarantee the same list of tags across all splits. For autotagging.tsv, this results in 55,525 tracks annotated by 87 genre tags, 40 instrument tags, and 56 mood/theme tags available in the splits.
Splits are generated from autotagging.tsv, containing all tags. For each split, the related subsets (top50, genre, instrument, mood/theme) are built filtering out unrelated tags and tracks without any tags.
Some additional metadata from Jamendo (artist, album name, track title, release date, track URL) is available in raw.meta.tsv (56,693).
Statistics in stats
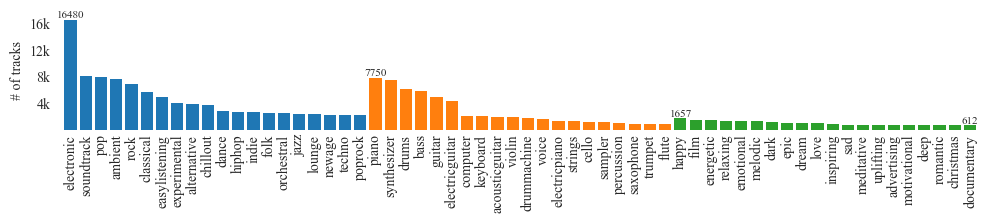
Statistics of number of tracks, albums and artists per tag sorted by number of artists.
Each directory has statistics for metadata file with the same name.
Here is the statistics for the autotagging set.
Statistics for subsets based on categories are not kept seperated due to it already included in autotagging.
Using the dataset
Requirements
- Python 3.7+
- Download dataset repository
git clone https://github.com/MTG/mtg-jamendo-dataset.git cd mtg-jamendo-dataset - Create virtual environment and install requirements
python3 -m venv venv source venv/bin/activate pip install -r scripts/requirements.txt
The original requirements are kept in reguirements-orig.txt
Downloading the data
All audio is distributed in 320kbps MP3 format. We recommend using this version of audio by default. For smaller download sizes, we also provide a lower-bitrate mono version of the same audio (converted from the full quality version to mono LAME VBR 2 lame -V 2). In addition we provide precomputed mel-spectrograms which are distributed as NumPy Arrays in NPY format (see computation parameters in the code). We also provide precomputed statistical features from Essentia (used in the AcousticBrainz music database) in JSON format. The audio files and the NPY/JSON files are split into folders packed into TAR archives.
We provide the following data subsets:
raw_30s/audio- all available audio forraw_30s.tsvin full quality (508 GB)raw_30s/audio-low- all available audio forraw_30s.tsvin low quality (156 GB)raw_30s/melspecs- mel-spectrograms forraw_30s.tsv(229 GB)autotagging-moodtheme/audio- audio for the mood/theme subsetautotagging_moodtheme.tsvin full quality (152 GB)autotagging-moodtheme/audio-low- audio for the mood/theme subsetautotagging_moodtheme.tsvin low quality (46 GB)autotagging-moodtheme/melspecs- mel-spectrograms for theautotagging_moodtheme.tsvsubset (68 GB)
We provide a script to download and validate all files in the dataset. See its help message for more information:
python3 scripts/download/download.py -h
usage: download.py [-h] [--dataset {raw_30s,autotagging_moodtheme}]
[--type {audio,audio-low,melspecs,acousticbrainz}]
[--from {mtg,mtg-fast}] [--unpack] [--remove]
outputdir
Download the MTG-Jamendo dataset
positional arguments:
outputdir directory to store the dataset
options:
-h, --help show this help message and exit
--dataset {raw_30s,autotagging_moodtheme}
dataset to download (default: raw_30s)
--type {audio,audio-low,melspecs,acousticbrainz}
type of data to download (audio, audio in low quality,
mel-spectrograms, AcousticBrainz features) (default: audio)
--from {mtg,mtg-fast}
download from MTG (server in Spain, slow),
or fast MTG mirror (Finland) (default: mtg-fast)
--unpack unpack tar archives (default: False)
--remove remove tar archives while unpacking one by one (use to
save disk space) (default: False)
For example, to download audio for the autotagging_moodtheme.tsv subset, unpack and validate all tar archives:
mkdir /path/to/download
python3 scripts/download/download.py --dataset autotagging_moodtheme --type audio /path/to/download --unpack --remove
Unpacking process is run after tar archive downloads are complete and validated. In the case of download errors, re-run the script to download missing files.
Due to the large size of the dataset, it can be useful to include the --remove flag to save disk space: in this case, tar archive are unpacked and immediately removed one by one.
Loading data in python
Assuming you are working in scripts folder
import commons
input_file = '../data/autotagging.tsv'
tracks, tags, extra = commons.read_file(input_file)
tracks is a dictionary with track_id as key and track data as value:
{
1376256: {
'artist_id': 490499,
'album_id': 161779,
'path': '56/1376256.mp3',
'duration': 166.0,
'tags': [
'genre---easylistening',
'genre---downtempo',
'genre---chillout',
'mood/theme---commercial',
'mood/theme---corporate',
'instrument---piano'
],
'genre': {'chillout', 'downtempo', 'easylistening'},
'mood/theme': {'commercial', 'corporate'},
'instrument': {'piano'}
}
...
}
tags contains mapping of tags to track_id:
{
'genre': {
'easylistening': {1376256, 1376257, ...},
'downtempo': {1376256, 1376257, ...},
...
},
'mood/theme': {...},
'instrument': {...}
}
extra has information that is useful to format output file, so pass it to write_file if you are using it, otherwise you can just ignore it
Reproduce postprocessing & statistics
- Recompute statistics for
rawandraw_30spython3 scripts/get_statistics.py data/raw.tsv stats/raw python3 scripts/get_statistics.py data/raw_30s.tsv stats/raw_30s - Clean tags and recompute statistics (
raw_30s_cleantags)python3 scripts/clean_tags.py data/raw_30s.tsv data/tag_map.json data/raw_30s_cleantags.tsv python3 scripts/get_statistics.py data/raw_30s_cleantags.tsv stats/raw_30s_cleantags - Filter out tags with low number of unique artists and recompute statistics (
raw_30s_cleantags_50artists)python3 scripts/filter_fewartists.py data/raw_30s_cleantags.tsv 50 data/raw_30s_cleantags_50artists.tsv --stats-directory stats/raw_30s_cleantags_50artists -
autotaggingfile indataand folder instatsis a symbolic link toraw_30s_cleantags_50artists - Visualize top 20 tags per category
python3 scripts/visualize_tags.py stats/autotagging 20 # generates top20.pdf figure
Recreate subsets
- Create subset with only top50 tags by number of tracks
python3 scripts/filter_toptags.py data/autotagging.tsv 50 data/autotagging_top50tags.tsv --stats-directory stats/autotagging_top50tags --tag-list data/tags/tags_top50.txt python3 scripts/split_filter_subset.py data/splits autotagging autotagging_top50tags --subset-file data/tags/top50.txt - Create subset with only mood/theme tags (or other category: genre, instrument)
python3 scripts/filter_category.py data/autotagging.tsv mood/theme data/autotagging_moodtheme.tsv --tag-list data/tags/moodtheme.txt python3 scripts/split_filter_subset.py data/splits autotagging autotagging_moodtheme --category mood/theme
Reproduce experiments
- Preprocessing
python3 scripts/baseline/get_npy.py run 'your_path_to_spectrogram_npy' - Train
python3 scripts/baseline/main.py --mode 'TRAIN' - Test
python3 scripts/baseline/main.py --mode 'TEST'optional arguments: --batch_size batch size (default: 32) --mode {'TRAIN', 'TEST'} train or test (default: 'TRAIN') --model_save_path path to save trained models (default: './models') --audio_path path of the dataset (default='/home') --split {0, 1, 2, 3, 4} split of data to use (default=0) --subset {'all', 'genre', 'instrument', 'moodtheme', 'top50tags'} subset to use (default='all')
Results
- ML4MD2019: 5 splits, 5 tag sets (3 categories, top50, all)
- Mediaeval2019: split-0, mood/theme category
Related Datasets
The MTG-Jamendo Dataset can be linked to related datasets tailored to specific applications.
Music Classification Annotations
The Music Classification Annotations contains annotations for the split-0 test set according to the taxonomies of 15 existing music classification datasets including genres, moods, danceability, voice/instrumental, gender, and tonal/atonal. These labels are suitable for training individual classifiers or learning everything in a multi-label setup (auto-tagging). Most of the taxonomies were annotated by three different annotators. We provide the subset of annotations with perfect inter-annotator agreement ranging from 411 to 8756 tracks depending on the taxonomy.
Song Describer
Song Describer Dataset contains ~1.1k captions for 706 permissively licensed music recordings. It is designed for use in evaluation of models that address music-and-language tasks such as music captioning, text-to-music generation and music-language retrieval. The dataset was built using the Song Describer platform for crowdsourcing music captions (audio-text pairs) for audio tracks in MTG-Jamendo.
MuChoMusic
MuChoMusic is a benchmark dataset for evaluating music understanding in multimodal audio-language models. It comprises 1187 multiple-choice questions, all validated by human annotators, associated with 644 music tracks sourced from two publicly available music datasets, including MTG-Jamendo.
ManyMusic
ManyMusic Stimuli is a music audio dataset designed for human experiments on musical emotions. This is part of the ManyMusic project, which aims to deep-phenotype affective experience evoked by music.
Research challenges using the dataset
- MediaEval 2019 Emotion and Theme Recognition in Music
- MediaEval 2020 Emotion and Theme Recognition in Music
- MediaEval 2021 Emotion and Theme Recognition in Music
Citing the dataset
Please consider citing the following publication when using the dataset:
Bogdanov, D., Won M., Tovstogan P., Porter A., & Serra X. (2019). The MTG-Jamendo Dataset for Automatic Music Tagging. Machine Learning for Music Discovery Workshop, International Conference on Machine Learning (ICML 2019).
@conference {bogdanov2019mtg,
author = "Bogdanov, Dmitry and Won, Minz and Tovstogan, Philip and Porter, Alastair and Serra, Xavier",
title = "The MTG-Jamendo Dataset for Automatic Music Tagging",
booktitle = "Machine Learning for Music Discovery Workshop, International Conference on Machine Learning (ICML 2019)",
year = "2019",
address = "Long Beach, CA, United States",
url = "http://hdl.handle.net/10230/42015"
}
License
- The code in this repository is licensed under Apache 2.0
- The metadata is licensed under a CC BY-NC-SA 4.0.
- The audio files are licensed under Creative Commons licenses, see individual licenses for details in
audio_licenses.txt.
Copyright 2019-2023 Music Technology Group
Please note that the MTG-Jamendo Dataset is made available solely for non-commercial research and academic use. Any other use, including but not limited to commercial applications, requires prior written authorization from Jamendo S.A. For any commercial use requests, please contact Jamendo’s licensing team at hello@jamendo.com to obtain a license adapted to your project. Commercial use is defined as any use that is intended for or directed toward commercial advantage or monetary compensation, including but not limited to uses generating revenue through advertising, affiliate programs, or product integration.
Acknowledgments
This work was funded by the predoctoral grant MDM-2015-0502-17-2 from the Spanish Ministry of Economy and Competitiveness linked to the Maria de Maeztu Units of Excellence Programme (MDM-2015-0502).
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 765068.
This work has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 688382 “AudioCommons”.
