TensorFlow models in Essentia
19 Oct 2019Audio Signal Processing and Music Information Retrieval evolve very fast and there is a tendency to rely more and more on Deep Learning solutions. For this reason, we see the necessity to support these solutions in Essentia to keep up with the state of the art. After having worked on this for the past months, we are delighted to present you a new set of algorithms and models that employ TensorFlow in Essentia. These algorithms are suited for inference tasks and offer the flexibility of use, easy extensibility, and (in some cases) real-time inference.
In this post, we will show how to install Essentia with TensorFlow support, how to prepare your pre-trained models, and how to use them for prediction in both streaming and standard modes. See our next post for the list of all models available in Essentia. For now, the installation steps are only available for Linux. Nevertheless, we are planning to support other platforms too.
Installing Essentia with TensorFlow
From PyPI wheels
For convenience, we have built special Python 3 Linux wheels for using Essentia with TensorFlow that can be installed with pip. These wheels include the required shared library for TensorFlow 1.15. Note that a pip version ≥19.3 is required (you should be fine creating a new virtualenv environment as it will contain an appropriate pip version).
pip3 install essentia-tensorflow
Building Essentia from source
A more flexible option is to build the library from source. This way we have the freedom to choose the TensorFlow version to use, which may be useful to ensure compatibility for certain models. In this case, we keep using version 1.15.
- At least pip version ≥19.3 is required:
pip3 install --upgrade pip - Install TensorFlow:
pip3 install tensorflow==1.15.0 - Clone Essentia:
git clone https://github.com/MTG/essentia.git - Run
setup_from_python.sh(may requiresudo). This script exposes the shared libraries contained in the TensorFlow wheel so we can link against them:cd essentia && src/3rdparty/tensorflow/setup_from_python.sh - Install the dependencies for Essentia with Python 3 (may require
sudo):apt-get install build-essential libyaml-dev libfftw3-dev libavcodec-dev libavformat-dev libavutil-dev libavresample-dev python-dev libsamplerate0-dev libtag1-dev libchromaprint-dev python-six python3-dev python3-numpy-dev python3-numpy python3-yaml libeigen3-dev - Configure Essentia with TensorFlow and Python 3:
python3 waf configure --build-static --with-python --with-tensorflow - Build everything:
python3 waf - Install:
python3 waf install
Auto-tagging with MusiCNN in Streaming mode
As an example, let’s try to use MusiCNN, a pre-trained auto-tagging model based on Convolutional Neural Networks (CNNs). There are versions trained on different datasets. In this case, we will consider the model relying on the subset of Million Song Dataset annotated by last.fm tags that was trained on the top 50 tags.
Here we are reproducing this blogpost as a demonstration of how simple it is to incorporate a model into our framework. All we need is to get the model in Protobuf format (we provide more pre-made models on our webpage) and obtain its labels and the names of the input and output layers. If the names of the layers are not supplied there are plenty of online resources explaining how to inspect the model to get those.
modelName = 'msd-musicnn-1.pb'
input_layer = 'model/Placeholder'
output_layer = 'model/Sigmoid'
msd_labels = ['rock','pop','alternative','indie','electronic','female vocalists','dance','00s','alternative rock','jazz','beautiful','metal','chillout','male vocalists','classic rock','soul','indie rock','Mellow','electronica','80s','folk','90s','chill','instrumental','punk','oldies','blues','hard rock','ambient','acoustic','experimental','female vocalist','guitar','Hip-Hop','70s','party','country','easy listening','sexy','catchy','funk','electro','heavy metal','Progressive rock','60s','rnb','indie pop','sad','House','happy']
One of the keys to making predictions faster is the use of our C++ extractor. Essentia’s algorithm for mel-spectrogram offers parameters that make it possible to reproduce the features from most of the well-known audio analysis libraries. In this case, we are reproducing the training features that were computed with Librosa:
# analysis parameters
sampleRate = 16000
frameSize=512
hopSize=256
# mel bands parameters
numberBands=96
weighting='linear'
warpingFormula='slaneyMel'
normalize='unit_tri'
# model parameters
patchSize = 187
First of all, we instantiate the required algorithms using the streaming mode of Essentia:
from essentia.streaming import *
from essentia import Pool, run
filename = 'your/amazing/song.mp3'
# Algorithms for mel-spectrogram computation
audio = MonoLoader(filename=filename, sampleRate=sampleRate)
fc = FrameCutter(frameSize=frameSize, hopSize=hopSize)
w = Windowing(normalized=False)
spec = Spectrum()
mel = MelBands(numberBands=numberBands, sampleRate=sampleRate,
highFrequencyBound=sampleRate // 2,
inputSize=frameSize // 2 + 1,
weighting=weighting, normalize=normalize,
warpingFormula=warpingFormula)
# Algorithms for logarithmic compression of mel-spectrograms
shift = UnaryOperator(shift=1, scale=10000)
comp = UnaryOperator(type='log10')
# This algorithm cuts the mel-spectrograms into patches
# according to the model's input size and stores them in a data
# type compatible with TensorFlow
vtt = VectorRealToTensor(shape=[1, 1, patchSize, numberBands])
# Auxiliar algorithm to store tensors into pools
ttp = TensorToPool(namespace=input_layer)
# The core TensorFlow wrapper algorithm operates on pools
# to accept a variable number of inputs and outputs
tfp = TensorflowPredict(graphFilename=modelName,
inputs=[input_layer],
outputs=[output_layer])
# Algorithms to retrieve the predictions from the wrapper
ptt = PoolToTensor(namespace=output_layer)
ttv = TensorToVectorReal()
# Another pool to store output predictions
pool = Pool()
Then we connect all the algorithms:
audio.audio >> fc.signal
fc.frame >> w.frame
w.frame >> spec.frame
spec.spectrum >> mel.spectrum
mel.bands >> shift.array
shift.array >> comp.array
comp.array >> vtt.frame
vtt.tensor >> ttp.tensor
ttp.pool >> tfp.poolIn
tfp.poolOut >> ptt.pool
ptt.tensor >> ttv.tensor
ttv.frame >> (pool, output_layer)
# Store mel-spectrograms to reuse them later in this tutorial
comp.array >> (pool, "melbands")
Now we can run the Network and measure the prediction time:
from time import time
start_time = time()
run(audio)
print('Prediction time: {:.2f}s'.format(time() - start_time))
Prediction time: 3.62s
Now let’s check what are the most likely tags in this song by averaging the predictions over the time:
import numpy as np
print('Most predominant tags:')
for i, l in enumerate(np.mean(pool[output_layer],
axis=0).argsort()[-3:][::-1], 1):
print('{}: {}'.format(i, msd_labels[l]))
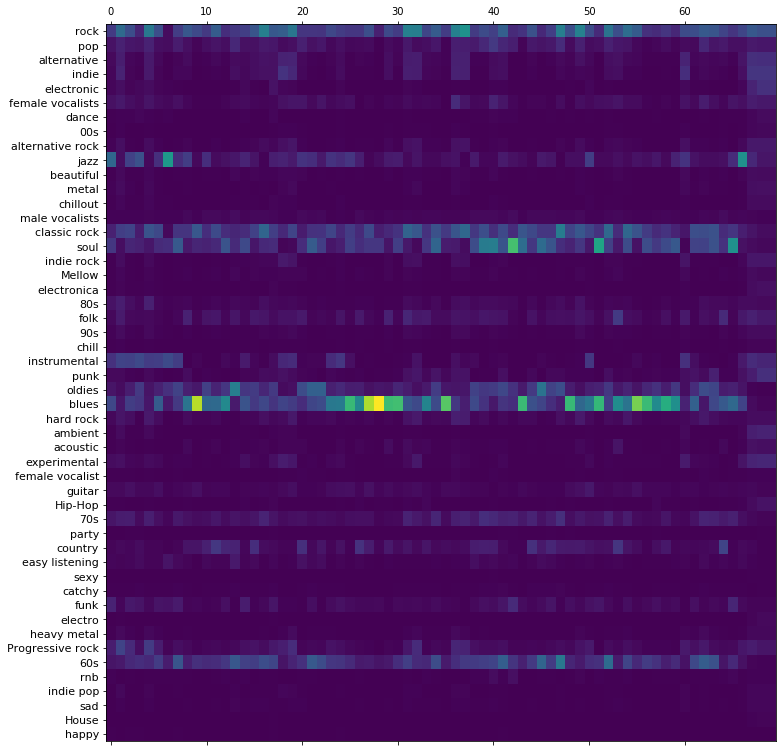
Most predominant tags:
1: blues
2: rock
3: classic rock
Also, we can see the evolution of tag activations over time in a taggram where columns correspond to consecutive input patches:
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = [12, 20]
f, ax = plt.subplots()
ax.matshow(pool[output_layer].T, aspect=1.5)
_ = plt.yticks(np.arange(50), msd_labels, fontsize=11)
Standard mode
The new algorithms are also available in the standard mode where they can be called as regular functions. This provides more flexibility in order to integrate them with a 3rd-party code in Python:
import essentia.standard as es
predict = es.TensorflowPredict(graphFilename=modelName,
inputs=[input_layer],
outputs=[output_layer])
in_pool = Pool()
In this example we’ll take advantage of the previously computed mel-spectrograms:
bands = pool['melbands']
discard = bands.shape[0] % patchSize # Would not fit into the patch.
bands = np.reshape(bands[:-discard,:], [-1, patchSize, numberBands])
batch = np.expand_dims(bands, 2)
in_pool.set('model/Placeholder', batch)
out_pool = predict(in_pool)
print('Most predominant tags:')
for i, l in enumerate(np.mean(out_pool[output_layer].squeeze(),
axis=0).argsort()[-3:][::-1], 1):
print('{}: {}'.format(i, msd_labels[l]))
Most predominant tags:
1: blues
2: rock
3: classic rock
How fast is it?
Let’s compare with the original Python implementation:
from subprocess import check_output
import os
start_time = time()
out = check_output(['python3','-m', 'musicnn.tagger',
filename, '--print', '--model', 'MSD_musicnn'])
print('Prediction time: {:.2f}s'.format(time() - start_time))
print(out)
Prediction time: 10.38s
Computing spectrogram (w/ librosa) and tags (w/ tensorflow)..
done!
[barry_white-you_heart_and_soul.mp3] Top3 tags:
- blues
- rock
- classic rock
Which is more than two times the time it took in Essentia. Great!
Using TensorFlow frozen models
In order to maximize efficiency, we only support frozen TensorFlow models. By freezing a model its variables are converted into constant values allowing for some optimizations.
Frozen models are easy to generate given a TensorFlow architecture and its weights. In our case, we have used the following script where our architecture is defined on an external method DEFINE_YOUR_ARCHITECTURE() and the weights are loaded from a CHECKPOINT_FOLDER/:
import tensorflow as tf
model_fol = 'YOUR/MODEL/FOLDER/'
output_graph = 'YOUR_MODEL_FILE.pb'
with tf.name_scope('model'):
DEFINE_YOUR_ARCHITECTURE()
sess = tf.Session()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess, 'CHECKPOINT_FOLDER/')
gd = sess.graph.as_graph_def()
for node in gd.node:
if node.op == 'RefSwitch':
node.op = 'Switch'
for index in range(len(node.input)):
if 'moving_' in node.input[index]:
node.input[index] = node.input[index] + '/read'
elif node.op == 'AssignSub':
node.op = 'Sub'
if 'use_locking' in node.attr: del node.attr['use_locking']
elif node.op == 'AssignAdd':
node.op = 'Add'
if 'use_locking' in node.attr: del node.attr['use_locking']
elif node.op == 'Assign':
node.op = 'Identity'
if 'use_locking' in node.attr: del node.attr['use_locking']
if 'validate_shape' in node.attr: del node.attr['validate_shape']
if len(node.input) == 2:
node.input[0] = node.input[1]
del node.input[1]
node_names =[n.name for n in gd.node]
output_graph_def = tf.graph_util.convert_variables_to_constants(
sess, gd, node_names)
# Write to Protobuf format
tf.io.write_graph(output_graph_def, model_fol, output_graph, as_text=False)
sess.close()
[ news ] [ tensorflow ]