A collection of TensorFlow models for Essentia
16 Jan 2020Note: the models were updated on 2020-07-08 due to a new name convention and some upgrades. See the full CHANGELOG for more details.
In our last post, we introduced the TensorFlow wrapper for Essentia. It can be used with virtually any TensorFlow model and here we present a collection of models we supply with Essentia out of the box.
First, we prepared a set of pre-trained auto-tagging models achieving state of-the-art performance. Then, we used those models as feature extractors to generate a set of transfer learning classifiers trained on our in-house datasets.
Along with the models we provide helper algorithms that allow performing predictions in just a couple of lines. Also, we include C++ extractors that could be built statically to use as standalone executables.
Supplied models
Auto-tagging models
Our auto-tagging models were pre-trained as part of Jordi Pons’ Ph.D. Thesis [1]. They were trained on two research datasets, MSD and MTT, to predict top 50 tags therein. Check the original repository for more details about the training process.
The following table shows the available architectures and the datasets used for training. For every model, its complexity is reported in terms of the number of trainable parameters. The models were trained and evaluated using the standardized train/test splits proposed for these datasets in research. The performance of the models is indicated in terms of ROC-AUC and PR-AUC obtained on the test splits. Additionally, the table provides download links for the models and README files containing the output labels, the name of the relevant layers and some details about the training datasets.
| Architecture | Dataset | Params. | ROC-AUC | PR-AUC | Model | README |
|---|---|---|---|---|---|---|
| MusiCNN | MSD | 790k | 0.88 | 0.29 | msd-musicnn | README |
| MusiCNN | MTT | 790k | 0.91 | 0.38 | mtt-musicnn | README |
| VGG | MSD | 605k | 0.88 | 0.28 | msd-vgg | README |
| VGG | MTT | 605k | 0.90 | 0.38 | mtt-vgg | README |
Transfer learning classifiers
In transfer learning, a model is first trained on a source task (typically with a greater amount of available data) to leverage the obtained knowledge in a smaller target task. In this case, we considered the aforementioned MusiCNN models and a big VGG-like (VGGish) model as source tasks. As target tasks, we considered our in-house classification datasets listed below. We use the penultimate layer of the source task models as feature extractors for small classifiers consisting of two fully connected layers.
The following tables present all trained classifiers in genre, mood and miscellaneous task categories. For each classifier, its source task name represents a combination of the architecture and the training dataset used. Its complexity is reported in terms of the number of trainable parameters. The performance of each model is measured in terms of normalized accuracy (Acc.) in a 5-fold cross-validation experiment conducted before the final classifier model was trained on all data.
Genre
| Source task | Target task | Params. | Acc. | Model | README |
|---|---|---|---|---|---|
| MusiCNN_MSD | genre_dortmund | 790k | 0.51 | genre_dortmund-musicnn-msd | README |
| MusiCNN_MSD | genre_electronic | 790k | 0.95 | genre_electronic-musicnn-msd | README |
| MusiCNN_MSD | genre_rosamerica | 790k | 0.92 | genre_rosamerica-musicnn-msd | README |
| MusiCNN_MSD | genre_tzanetakis | 790k | 0.83 | genre_tzanetakis-musicnn-msd | README |
| MusiCNN_MTT | genre_dortmund | 790k | 0.44 | genre_dortmund-musicnn-mtt | README |
| MusiCNN_MTT | genre_electronic | 790k | 0.71 | genre_electronic-musicnn-mtt | README |
| MusiCNN_MTT | genre_rosamerica | 790k | 0.92 | genre_rosamerica-musicnn-mtt | README |
| MusiCNN_MTT | genre_tzanetakis | 790k | 0.80 | genre_tzanetakis-musicnn-mtt | README |
| VGGish_AudioSet | genre_dortmund | 62M | 0.52 | genre_dortmund-vggish-audioset | README |
| VGGish_AudioSet | genre_electronic | 62M | 0.93 | genre_electronic-vggish-audioset | README |
| VGGish_AudioSet | genre_rosamerica | 62M | 0.94 | genre_rosamerica-vggish-audioset | README |
| VGGish_AudioSet | genre_tzanetakis | 62M | 0.86 | genre_tzanetakis-vggish-audioset | README |
Mood
| Source task | Target task | Params. | Acc. | Model | README |
|---|---|---|---|---|---|
| MusiCNN_MSD | mood_acoustic | 790k | 0.90 | mood_acoustic-musicnn-msd | README |
| MusiCNN_MSD | mood_aggressive | 790k | 0.95 | mood_aggressive-musicnn-msd | README |
| MusiCNN_MSD | mood_electronic | 790k | 0.95 | mood_electronic-musicnn-msd | README |
| MusiCNN_MSD | mood_happy | 790k | 0.81 | mood_happy-musicnn-msd | README |
| MusiCNN_MSD | mood_party | 790k | 0.89 | mood_party-musicnn-msd | README |
| MusiCNN_MSD | mood_relaxed | 790k | 0.90 | mood_relaxed-musicnn-msd | README |
| MusiCNN_MSD | mood_sad | 790k | 0.86 | mood_sad-musicnn-msd | README |
| MusiCNN_MTT | mood_acoustic | 790k | 0.93 | mood_acoustic-musicnn-mtt | README |
| MusiCNN_MTT | mood_aggressive | 790k | 0.96 | mood_aggressive-musicnn-mtt | README |
| MusiCNN_MTT | mood_electronic | 790k | 0.91 | mood_electronic-musicnn-mtt | README |
| MusiCNN_MTT | mood_happy | 790k | 0.79 | mood_happy-musicnn-mtt | README |
| MusiCNN_MTT | mood_party | 790k | 0.92 | mood_party-musicnn-mtt | README |
| MusiCNN_MTT | mood_relaxed | 790k | 0.88 | mood_relaxed-musicnn-mtt | README |
| MusiCNN_MTT | mood_sad | 790k | 0.85 | mood_sad-musicnn-mtt | README |
| VGGish_AudioSet | mood_acoustic | 62M | 0.94 | mood_acoustic-vggish-audioset | README |
| VGGish_AudioSet | mood_aggressive | 62M | 0.98 | mood_aggressive-vggish-audioset | README |
| VGGish_AudioSet | mood_electronic | 62M | 0.93 | mood_electronic-vggish-audioset | README |
| VGGish_AudioSet | mood_happy | 62M | 0.86 | mood_happy-vggish-audioset | README |
| VGGish_AudioSet | mood_party | 62M | 0.91 | mood_party-vggish-audioset | README |
| VGGish_AudioSet | mood_relaxed | 62M | 0.89 | mood_relaxed-vggish-audioset | README |
| VGGish_AudioSet | mood_sad | 62M | 0.89 | mood_sad-vggish-audioset | README |
Miscellaneous
| Source task | Target task | Params. | Acc. | Model | README |
|---|---|---|---|---|---|
| MusiCNN_MSD | danceability | 790k | 0.93 | danceability-musicnn-msd | README |
| MusiCNN_MSD | gender | 790k | 0.88 | gender-musicnn-msd | README |
| MusiCNN_MSD | tonal_atonal | 790k | 0.60 | tonal_atonal-musicnn-msd | README |
| MusiCNN_MSD | voice_instrumental | 790k | 0.98 | voice_instrumental-musicnn-msd | README |
| MusiCNN_MTT | danceability | 790k | 0.91 | danceability-musicnn-mtt | README |
| MusiCNN_MTT | gender | 790k | 0.87 | gender-musicnn-mtt | README |
| MusiCNN_MTT | tonal_atonal | 790k | 0.91 | tonal_atonal-musicnn-mtt | README |
| MusiCNN_MTT | voice_instrumental | 790k | 0.98 | voice_instrumental-musicnn-mtt | README |
| VGGish_AudioSet | danceability | 62M | 0.94 | danceability-vggish-audioset | README |
| VGGish_AudioSet | gender | 62M | 0.84 | gender-vggish-audioset | README |
| VGGish_AudioSet | tonal_atonal | 62M | 0.97 | tonal_atonal-vggish-audioset | README |
| VGGish_AudioSet | voice_instrumental | 62M | 0.98 | voice_instrumental-vggish-audioset | README |
Architecture details
- MusiCNN is a musically-motivated Convolutional Neural Network. It uses vertical and horizontal convolutional filters aiming to capture timbral and temporal patterns, respectively. The model contains 6 layers and 790k parameters.
- VGG is an architecture from computer vision based on a deep stack of commonly used 3x3 convolutional filters. It contains 5 layers with 128 filters each. Batch normalization and dropout are applied before each layer. The model has 605k trainable parameters. We are using the implementation by Jordi Pons.
- VGGish [2, 3] follows the configuration E from the original implementation for computer vision, with the difference that the number of output units is set to 3087. This model has 62 million parameters.
Datasets details
- MSD contains 200k tracks from the train set of the publicly available Million Song Dataset (MSD) annotated by tags from Last.fm. Only top 50 tags are used.
- MTT contains 25k tracks from Magnatune with tags by human annotators. Only top 50 tags are used.
- AudioSet contains 1.8 million audio clips from Youtube annotated with the AudioSet taxonomy, not specific to music.
- MTG in-house datasets are a collection of small, highly curated datasets used for training classifiers. A set of SVM classifiers based on these datasets is also available.
| Dataset | Classes | Size |
|---|---|---|
| genre_dortmund | alternative, blues, electronic, folkcountry, funksoulrnb, jazz, pop, raphiphop, rock | 1820 |
| genre_gtzan | blues, classic, country, disco, hip hop, jazz, metal, pop, reggae, rock | 1000 |
| genre_rosamerica | classic, dance, hip hop, jazz, pop, rhythm and blues, rock, speech | 400 |
| genre_electronic | ambient, dnb, house, techno, trance | 250 |
| mood_acoustic | acoustic, not acoustic | 321 |
| mood_electronic | electronic, not electronic | 332 |
| mood_aggressive | aggressive, not aggressive | 280 |
| mood_relaxed | not relaxed, relaxed | 446 |
| mood_happy | happy, not happy | 302 |
| mood_sad | not sad, sad | 230 |
| mood_party | not party, party | 349 |
| danceability | danceable, not dancable | 306 |
| voice_instrumental | voice, instrumental | 1000 |
| gender | female, male | 3311 |
| tonal_atonal | atonal, tonal | 345 |
Helper algorithms
Algorithms for MusiCNN and VGG based models:
- TensorflowInputMusiCNN. Computes mel-bands with a particular parametrization specific to MusiCNN based models.
- TensorflowPredictMusiCNN. Makes predictions using MusiCNN models.
Algorithms for VGGish based models:
- TensorflowInputVGGish. Computes mel-bands with a particular parametrization specific to VGGish based models.
- TensorflowPredictVGGish. Makes predictions using VGGish models.
Usage examples
Let’s exemplify some use cases.
Auto-tagging
In this case, we are replicating the example of our previous post. With the new algorithms, the code is reduced to just a couple of lines!
import numpy as np
from essentia.standard import *
msd_labels = ['rock','pop','alternative','indie','electronic','female vocalists','dance','00s','alternative rock','jazz','beautiful','metal','chillout','male vocalists','classic rock','soul','indie rock','Mellow','electronica','80s','folk','90s','chill','instrumental','punk','oldies','blues','hard rock','ambient','acoustic','experimental','female vocalist','guitar','Hip-Hop','70s','party','country','easy listening','sexy','catchy','funk','electro','heavy metal','Progressive rock','60s','rnb','indie pop','sad','House','happy']
# Our models take audio streams at 16kHz
sr = 16000
# Instantiate a MonoLoader and run it in the same line
audio = MonoLoader(filename='/your/amazong/song.wav', sampleRate=sr)()
# Instatiate the tagger and pass it the audio
predictions = TensorflowPredictMusiCNN(graphFilename='msd-musicnn-1.pb')(audio)
# Retrieve the top_n tags
top_n = 3
# The shape of the predictions matrix is [n_patches, n_labels]
# Take advantage of NumPy to average them over the time axis
averaged_predictions = np.mean(predictions, axis=0)
# Sort the predictions and get the top N
for i, l in enumerate(averaged_predictions.argsort()[-top_n:][::-1], 1):
print('{}: {}'.format(i, msd_labels[l]))
1: electronic
2: chillout
3: ambient
Classification
In this example, we are using our genre_rosamerica classifier based on the VGGish embeddings. Note that this time we are using TensorflowPredictVGGish instead of TensorflowPredictMusiCNN so that the model is fed with the correct input features.
import numpy as np
from essentia.standard import *
labels = ['classic', 'dance', 'hip hop', 'jazz',
'pop', 'rnb', 'rock', 'speech']
sr = 16000
audio = MonoLoader(filename='/your/amazing/song.wav', sampleRate=sr)()
predictions = TensorflowPredictVGGish(graphFilename='genre_rosamerica-vggish-audioset-1.pb')(audio)
# Average predictions over the time axis
predictions = np.mean(predictions, axis=0)
order = predictions.argsort()[::-1]
for i in order:
print('{}: {:.3f}'.format(labels[i], predictions[i]))
hip hop: 0.411
dance: 0.397
jazz: 0.056
pop: 0.053
rnb: 0.051
rock: 0.011
classic: 0.004
speech: 0.001
Latent feature extraction
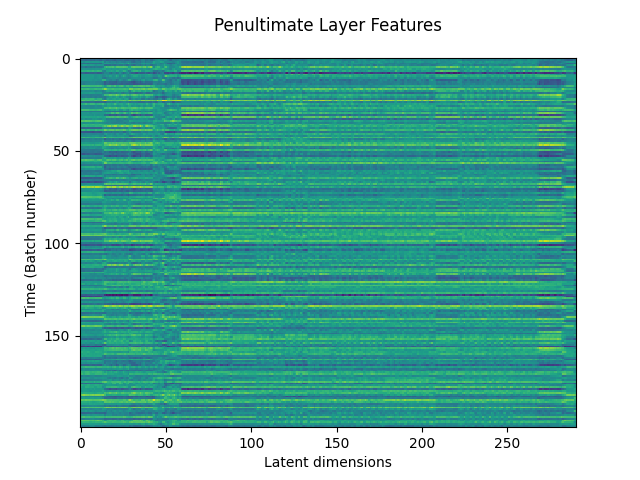
As the last example, let’s use one of the models as a feature extractor by retrieving the output of the penultimate layer. This is done by setting the output parameter in the predictor algorithm.
A list of the supported output layers is available in the README files supplied with the models.
from essentia.standard import MonoLoader, TensorflowPredictMusiCNN
sr = 16000
audio = MonoLoader(filename='/your/amazing/song.wav', sampleRate=sr)()
# Retrieve the output of the penultimate layer
penultimate_layer = TensorflowPredictMusiCNN(graphFilename='msd-musicnn-1.pb', output='model/dense/BiasAdd')(audio)
The following plot shows how these features look like:
References
[1] Pons, J., & Serra, X. (2019). musicnn: Pre-trained convolutional neural networks for music audio tagging. arXiv preprint arXiv:1909.06654.
[2] Gemmeke, J. et. al., AudioSet: An ontology and human-labelled dataset for audio events, ICASSP 2017.
[3] Hershey, S. et. al., CNN Architectures for Large-Scale Audio Classification, ICASSP 2017
[ news ] [ tensorflow ]