A Neural Parametric Singing Synthesizer
Sound examples
Contact: {merlijn.blaauw, jordi.bonada}@upf.edu
Published: 18 December 2017.
Presented at Interspeech 2017, August 20-24, 2017, Stockholm, Sweden.
Related works
Presented at ICASSP 2019, May 12-17, 2019, Brighton, UK.
[Seq2Seq feed-forward Transformer demos]
Presented at ICASSP 2020, May 4-8, 2020, Barcelona, Spain.
[Hybrid neural-parametric F0 model demos]
Presented at ICASSP 2020, May 4-8, 2020, Barcelona, Spain.
[Semi-supervised timbre model demos]
Submitted to ICASSP 2021, June 6-11, 2021, Toronto, Canada.
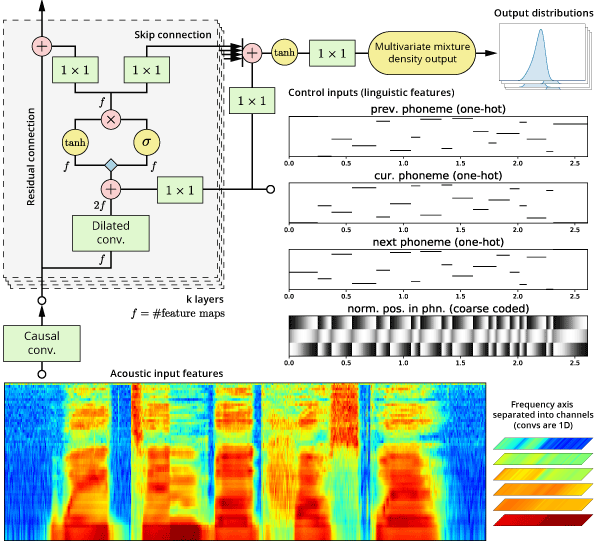
Demos
English male voice (M1) - Take the A train
In the following examples only timbre is generated by the model. Pitch and phonetic timings are extracted from a recording (in most cases of a different singer).
English female voice (F1) - Locked out of love
Spanish female voice (F2) - El último vals
Here "Soft VQ" and "Powerful VQ" are different voice qualities trained using smaller amounts of training data. Not discussed in paper or journal.
Japanese female voice (F3) - ふるさと (Furusato)
Japanese female voice (F3) - ハナミズキ (Hanamizuki)
In this example pitch and phonetic timings are predicted by the model from a "MIDI + lyrics"-like input score. Discussed in extended journal, but not original paper.
Acknowledgments
The datasets used for voices F1 and M1 are provided by Zya. The dataset used for voice F2 is provided by Voctro Labs. The dataset used for voice F3, "NIT SONG070 F001" by Nagoya Institute of Technology, is licensed under CC BY 3.0. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan X Pascal GPU used for this research.