Hybrid Neural-Parametric F0 Model for Singing Synthesis
Contact: {jordi.bonada, merlijn.blaauw}@upf.edu
Presented at ICASSP 2020, May 4-8, 2020, Barcelona, Spain.
[other singing synthesis demos]
Abstract
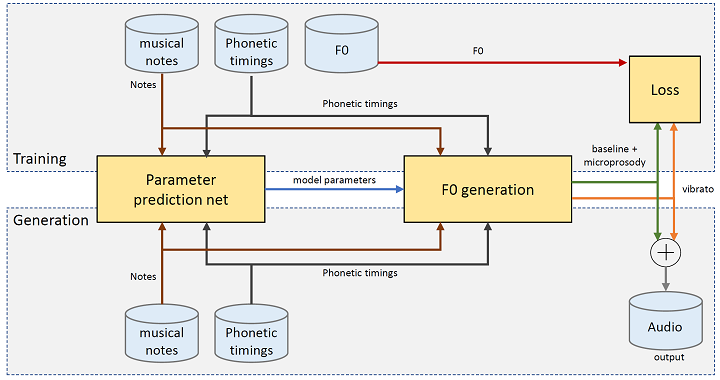
We propose a novel hybrid neural-parametric fundamental frequency generation model for singing voice synthesis. A recurrent neural network predicts the parameters of a flexible parametric F0 model, conditioned on a given input score. Rather than trying to directly match ground truth parameter values, we train the model with several loss functions derived from comparing the ground truth F0 curve and the one generated by the parametric model. Our proposed model can be trained from only F0 and phonetic timing information, without requiring any additional annotations, and is able to learn singing style characteristics from few data, e.g. just one song. We subjectively evaluate the effectiveness of our model compared to a baseline autoregressive model for cases of both large and small datasets.
Sound examples
Comparison of F0 generated curves by different models trained with the NIT-SONG070-F001 dataset.
Phonetic timings are obtained from a reference recording, while timbre is predicted by the NPSS model and synthesized with the WORLD vocoder.
Comparison
Acknowledgments
This work uses the public version of the NIT-SONG070-F001 dataset by Nagoya Institute of Technology, licensed under CC BY 3.0