Pitch extraction#
As seen in the melodic introduction of Carnatic and Hindustani, pitch time-series is a very relevant feature to tackle the melodic analysis of these music traditions, showing utility for many musicologically-relevant problems. Given the shortage of recordings for isolated predominant melodic instruments, this task has had to be tackled directly from mixture recordings. In this context, the task is referred as predominant pitch extraction (otherwise commonly referred as vocal pitch extraction when the source is the singing voice).
Historically, in the literature of computational analysis of Indian Art Music, this task has been tackled using knowledge-based approaches [RR10, SG12]. Melodia [SG12], typically combined with additional post-processing steps [GSIS15a], has been the preferred approach until today.
## Installing (if not) and importing compiam to the project
import importlib.util
if importlib.util.find_spec('compiam') is None:
## Bear in mind this will only run in a jupyter notebook / Collab session
%pip install compiam
import compiam
# Import extras and supress warnings to keep the tutorial clean
import os
import numpy as np
from pprint import pprint
import warnings
warnings.filterwarnings('ignore')
Let’s first print out the available tools we do have available to extract the pitch from Indian Art Music recordings.
pprint(compiam.melody.pitch_extraction.list_tools())
['FTANetCarnatic*', 'FTAResNetCarnatic*', 'Melodia']
Melodia#
Let’s extract the pitch from an audio sample using Melodia [SG12]. This is a salience-based method, meaning that it captures the most salient melodic segments in the time-frequency representation of the input signal, keeping and connecting the segments that are more likely to belong to the predominant melody, using heuristic rules. Make sure you check out the paper for further detail!
We first need to install essentia, which is the optional dependency required to load this tool.
%pip install essentia
# Importing and initializing a melodia instance
from compiam.melody.pitch_extraction import Melodia
melodia = Melodia()
# Running extraction for an example track
melodia_pitch_track = melodia.extract(
os.path.join(
"..", "audio", "mir_datasets", "saraga1.5_carnatic",
"Live at Vani Mahal by Sanjay Subrahmanyan", "Sri Raghuvara Sugunaalaya",
"Sanjay Subrahmanyan - Sri Raghuvara Sugunaalaya.mp3"
)
)
print("Shape of the output pitch:", np.shape(melodia_pitch_track))
Shape of the output pitch: (20675, 2)
We can infer from the shape the number of estimated pitch values, while the dimension 2 refers to (frequency values, time-stamps). Let us show the first 5 time-stamps here.
pprint(list(melodia_pitch_track[:5, 0]))
[0.0,
0.0029024943310657597,
0.005804988662131519,
0.008707482993197279,
0.011609977324263039]
Let’s now print out the final 5 pitch values.
pprint(list(melodia_pitch_track[-5:, 1]))
[220.00181579589844, 222.55812072753906, 222.55812072753906, 0.0, 0.0]
Melodia has been found, in the original paper experiments and also in the MIREX campaign, to decently work on Indian Art Music samples. However, recent DL-based models have claimed the state-of-the-art for the task of pitch extraction.
FTANet-Carnatic#
Maybe we can use a Carnatic-trained version of one of these models to extract the pitch? Let’s now import a DL model that learns to automatically extract the predominant melody from audio recordings. We will use FTANet [YSYL21]. This is an attention-based network that laverages and fuses information from frequency and periodicity domains to capture the right pitch values for the predominant source. It learns to focus on a particular source, using an additional branch that helps reducing the false alarm rate (detecting pitch values that do not correspond to the source we target).
To train this model we need a dataset that includes mixture recordings plus annotated pitch time-series for the source we aim at capturing the pitch from. This FTANet instance is trained with the Saraga Carnatic Melody Synth (SMCS), a dataset compiled and presented within the context of the work in [PRNP+23].
In the documentation we observe that this model is based on tensorflow, therefore we must install this dependency before importing it.
%pip install "tensorflow==2.15.0" "keras<3"
from compiam.melody.pitch_extraction import FTANetCarnatic
This is a non-trained instance!
Directly importing a ML/DL-based tool from the corresponding task initialises a non-trained instance. However, if a * appears at the end of the tool name when running .list_tools(), the pre-trained weights can be loaded using the compiam.load_model() wrapper.
In ths case, we are only interested in inference. Therefore, we might be able to load FTANet as an already trained model. For that, let’s print the models with available weights to load in compiam.
pprint(compiam.list_models())
['melody:deepsrgm',
'melody:ftanet-carnatic',
'melody:ftaresnet-carnatic-violin',
'melody:cae-carnatic',
'structure:dhrupad-bandish-segmentation',
'separation:cold-diff-sep',
'separation:mixer-model']
Cool! A Carnatic-trained FTANet is there. Therefore, let’s load it and run inference on an example track.
# Disabling tensorflow warnings and debugging info
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
# Importing tensorflow and disabling GPU usage
import tensorflow as tf
tf.config.set_visible_devices([], "GPU")
Let’s first deactivate the GPU usage, since we assume no CUDA-capable GPU is available in most of the cases. We import tensorflow and set the visible GPU devices to none. We also disable the tensorflow warnings in order to keep the tutorial clean.
Note
If you have an available GPU to allocate the model, get the index of the GPU (probably 0 if you have only a single instance) and change tf.config.set_visible_devices([], "GPU") for os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# Initializing an FTANet instance
ftanet_carnatic = compiam.load_model("melody:ftanet-carnatic")
# Importing and initializing again a melodia instance of comparison
from compiam.melody.pitch_extraction import Melodia
melodia = Melodia()
We will now initialize Saraga Carnatic dataset to get an example track, load it, and run inference using FTANet-Carnatic and Melodia, both accessed through compiam.
from compiam import load_dataset
saraga_carnatic = load_dataset(
"saraga_carnatic",
data_home=os.path.join("..", "audio", "mir_datasets")
)
saraga_tracks = saraga_carnatic.load_tracks()
example = saraga_tracks["109_Sri_Raghuvara_Sugunaalaya"]
# Predict!
melodia_pitch_track = melodia.extract(example.audio_path)
ftanet_pitch_track = ftanet_carnatic.predict(
example.audio_path,
out_step=melodia_pitch_track[1, 0], # Interpolating to same size
)
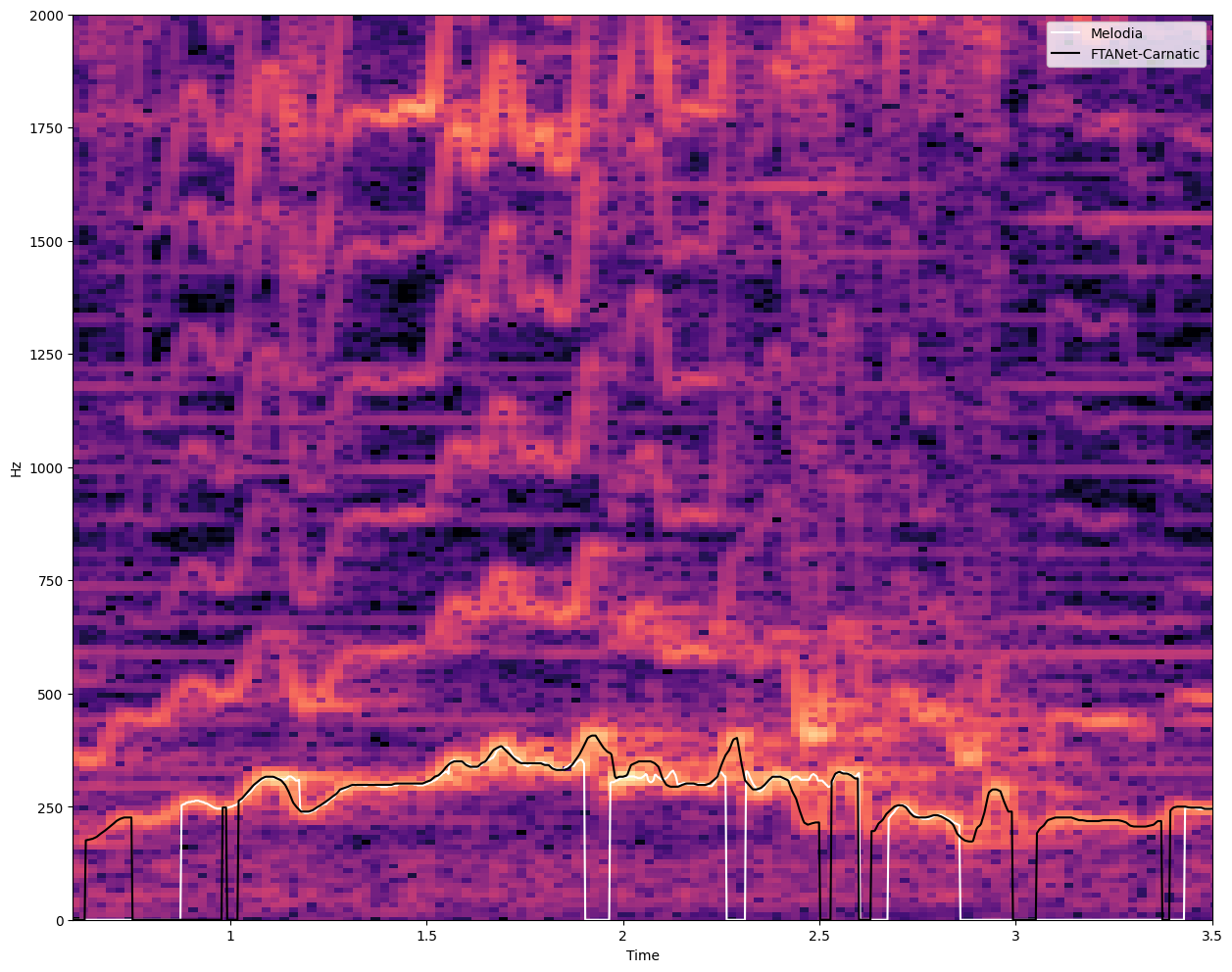
Let’s visualise the extracted pitch tracks on top of the spectrogram of the input signal.
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
y, sr = librosa.load(example.audio_path)
fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True, figsize=(15, 12))
D = librosa.amplitude_to_db(np.abs(librosa.stft(y)), ref=np.max)
img = librosa.display.specshow(D, y_axis='linear', x_axis='time', sr=sr, ax=ax);
ax.set_ylim(0, 2000)
ax.set_xlim(0.6, 3.5)
plt.plot(
melodia_pitch_track[:, 0], melodia_pitch_track[:, 1],
color="white", label="Melodia",
)
plt.plot(
ftanet_pitch_track[:, 0], ftanet_pitch_track[:, 1],
color="black",label="FTANet-Carnatic",
)
plt.legend()
plt.show()
Violin pitch tracking#
The FTANet-Carnatic in [PRNP+23] is trained to focus on the melody singing voice, ignoring the rest of the melodic instruments in the mix. However, the pipeline in [PRNP+23] can be extrapolated to other instruments in order to track their melodes. As seen, in Carnatic Music we have a very common accompanying melodic instrument: the violin, being the melodic counterpart of the harmonium in Hindustani Music.
As of compiam v0.4.0, we have integrated a violin tracking system which can be initialized by running:
compiam.load_model("melody:ftaresnet-carnatic-violin")
The model operates using the same mechanics as the vocal FTANetCarnatic. See the compIAM documentation and the official repository of the violin tracking model for more detail.
Some final thoughts#
Again, going through the melodic introduction of Carnatic and Hindustani Music, we note the importance of a reliable pitch extraction for the computational analysis of Indian Art Music. The task of pitch extraction has received quite a lot of attention recently and the state-of-the-art has been continuously moved forward, especially given the use of DL techniques. However, to the best of our knowledge, no DL-based pitch extraction has been trained or evaluated on Indian Art Music signals, the lack of data being the principal cause. The FTA-Net trained for Carnatic Music that we present in this walkthrough and that we have included in compiam has been trained with the Saraga Carnatic Melody Synth (SMCS), a recently released dataset that includes several hours of Carnatic Music recordings annotated with ground-truth vocal pitch data that have been artificially compiled. Similar pipelines to that show beneficial for a more reliable computational-based melodic study of Indian Art music traditions.