Melodic pattern dicovery#
Melodic pattern discovery is a core task within the melodic analysis of Indian Art Music, most of the approaches building on top of time-series of pitch [GSIS15a, GSIS16, GSIS15b, IDBM13, RRG+14]. In fact, [VK18] reviews the melodic recognition task in Carnatic Music and concludes that using pitch data drives to better performance. On the same line, a musically-relevant statistical analysis of melodic patterns is proposed in [VAM17], aiming at providing a more handy representation of this important aspect for Carnatic and Hindustani Music.
More recently, the task of melodic pattern discovery has been approached taking advantage of DL techniques by combining the learnt features from a complex autoencoder and an attention-based vocal pitch extraction model [NPRPS22a]. Multiple design choices of this entire process are informed by tradition characteristics.
## Installing (if not) and importing compiam to the project
import importlib.util
if importlib.util.find_spec('compiam') is None:
## Bear in mind this will only run in a jupyter notebook / Collab session
%pip install compiam
import compiam
# Import extras and supress warnings to keep the tutorial clean
import os
import numpy as np
from pprint import pprint
import warnings
warnings.filterwarnings('ignore')
Sañcara search#
In this walkthrough we demonstrate the task of repeated melodic motif identification in Carnatic Music. The methodologies used are presented in [NPRPS22a] and [PRNP+23] for which compIAM repository serves as the most up to date and well-maintained implementation.
In the compIAM documentation we can see that the tool we showcase in this page has torch as a dependency for the DL models.
%pip install torch
1. Data#
This notebook works with a performance from the Saraga Carnatic Dataset. This performance audio is not provided alongside this notebook as part of the compIAM package but can be downloaded manually following the instructions in the Access section of the provided link. Although we encourage the reader to try with their own Carnatic performance audio.
audio_path = os.path.join("..", "audio", "pattern_finding", "Koti Janmani.multitrack-vocal.mp3") # path to audio
raga = 'ritigaula' # carnatic raga
2. Pitch processing#
2.1 Predominant pitch extraction#
Owing to the the coarticulation (merging) of svaras through gamakas, musically salient units in Carnatic Music are often better characterised by continuous time series pitch data rather than transcription to symbolic notation [NPRPS22b, Pea16].
However, Carnatic Music constitutes a difficult case for vocal pitch extraction – although performances place strong emphasis on a monophonic melodic line from the soloist singer, heterophonic melodic elements also occur, for example from the accompanying violinist who shadows the melody of the soloist often at a lag and with variation. In addition, there are the sounds of the tanpura (plucked lute that creates an oscillating drone) and pitched percussion instruments [PRNP+23].
Here we use a pretrained FTA-Net model for the task. This is provided with the compIAM package via the compiam.load_model() function. The model is an attention-based network that leverages and fuses information from the frequency and periodicity domains to capture the correct pitch values for the predominant source. It learns to focus on this source by using an additional branch that helps reduce the false alarm rate (detecting pitch values that do not correspond to the source we target) [YSYL21].
This FTANet instance is trained on the Saraga Carnatic Melody Synth dataset (SMCS), a dataset including more than 1000 minutes of time-aligned and continuous vocal melody annotations for the Carnatic music tradition [PRNP+23]. See also the FTANet-Carnatic walkthrough in this tutorial.
ftanet = compiam.load_model("melody:ftanet-carnatic")
Extracting the vocal pitch track:
pitch_track = ftanet.predict(audio_path)
pitch = pitch_track[:,1] # Pitch in Hz
time = pitch_track[:,0] # Time in seconds
timestep = time[2]-time[1] # time in seconds between elements of pitch track
We can interpolate small silences to account for minor errors in the pitch exrraction process, typically caused by glottal sounds and sudden decrease of pitch salience in gamakas [NPRPS22b].
from compiam.utils.pitch import interpolate_below_length
pitch = interpolate_below_length(
pitch, # track to interpolate
0, # value to interpolate
350*0.001/timestep # maximum gap in number sequence elements to interpolate for
)
2.2 Visualising predominant pitch#
We can plot our pitch track using the visualisation tools in compiam.visualisation
from compiam.visualisation.pitch import plot_pitch, flush_matplotlib
from compiam.utils import ipy_audio
We want to accompany pitch plots with audio so load raw audio too.
# let's load the audio also
import librosa
sr = 44100 # sampling_rate
audio, _ = librosa.load(audio_path,sr=sr)
t1 = 304 # in seconds
t2 = 324 # in seconds
t1s = round(t1/timestep) # in sequence elements
t2s = round(t2/timestep) # in sequence elements
this_pitch = pitch[t1s:t2s]
this_time = time[t1s:t2s]
plot_pitch(this_pitch, this_time, title='Excerpt of Koti Jamani by The Akkarai Sisters')
ipy_audio(audio, t1, t2, sr=sr)
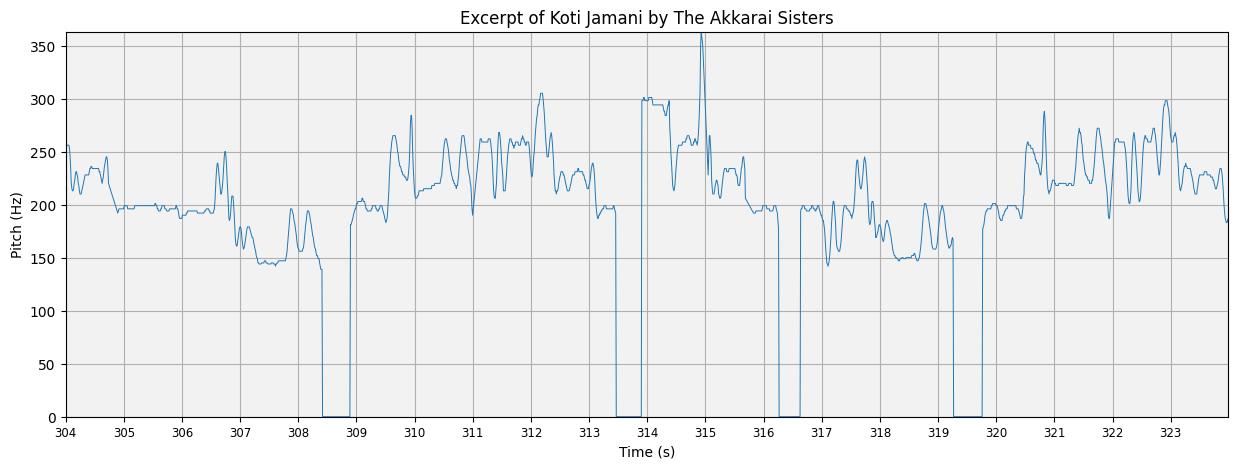
The plot is OK but we could definitely make it more interpretable. First of all, since silences are represented as 0Hz in our predominant pitch track, the interpolationm between points creates large drops to 0 for these regions. We can pass a binary mask to plot_pitch to tell it not to plot certain areas. In this case we want this mask to be 1 when there is non-silence (non-zero) and 1 otherwise:
silence_mask = this_pitch==0
plot_pitch(this_pitch, this_time, mask=silence_mask, title='Excerpt of Koti Jamani by The Akkarai Sisters')
ipy_audio(audio, t1, t2, sr=sr)
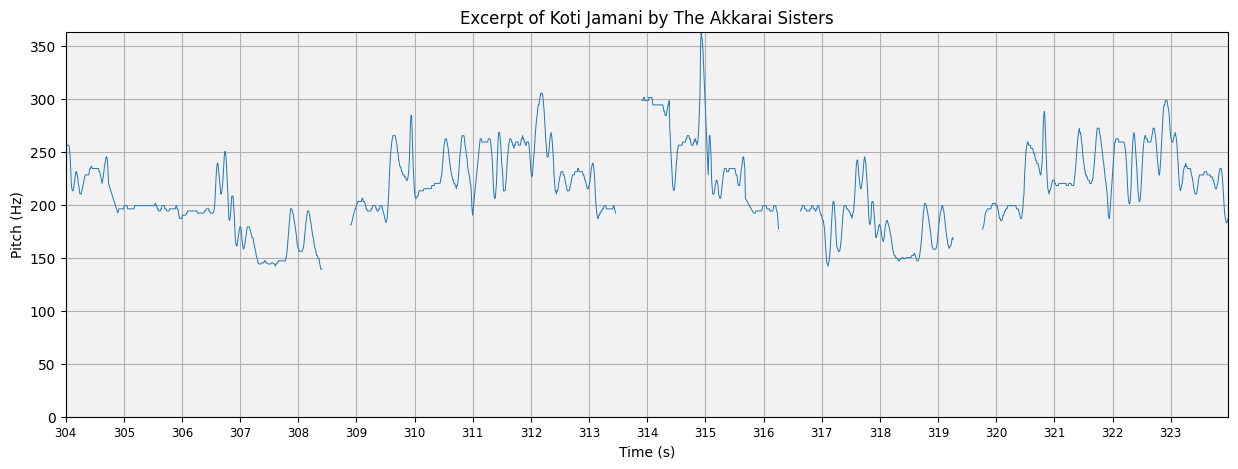
Pitch is often thought about in terms of it’s relationship to the tonic (Sa), which we can quantify using cents. A tonic identifier is provided in compiam.melody, or alternatively the tonic may be provided precomputed in the Saraga Dataset.
from compiam.melody import tonic_identification
#tonicExt = tonic_identification.TonicIndianMultiPitch()
tonic = 195.99
Passing this tonic to plot_pitch converts the plotted curve to cents:
plot_pitch(this_pitch, this_time, mask=silence_mask, tonic=tonic, cents=True, title='Excerpt of Koti Jamani by The Akkarai Sisters')
ipy_audio(audio, t1, t2, sr=sr)
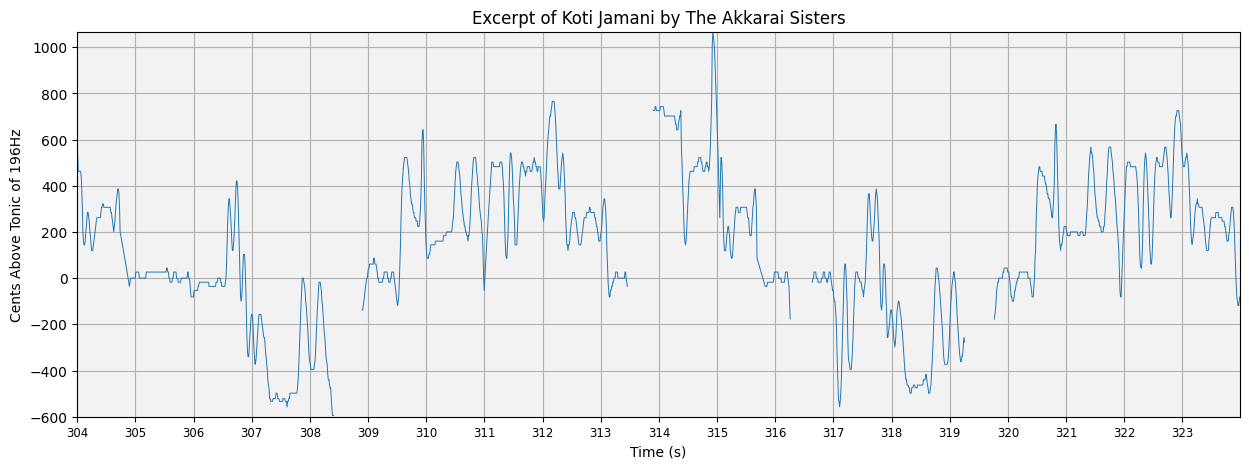
Finally we go one step further and replace the cents ticks on the y-axis with the expected svaras for this raga, plotted at their theoretical pitch positions on an equal tempered scale.
For a growing list of ragas, these theoretical svara:pitch mappings are available from compiam.utils.get_svara_pitch_carnatic.
from compiam.utils import get_svara_pitch_carnatic
It is not uncommon to observe variations in how raga names (and more broadly, Indian Art Music terms) are transliterated from their original Indian language to latin-script. This makes it difficult to create key value mappings using these terms. If an unknown raga is passed to get_svara_pitch_carnatic, a list of closest matches are suggested as alternatives (if any exists).
get_svara_pitch_carnatic(raga)
{-2400: 'S',
-1200: 'S',
0: 'S',
1200: 'S',
2400: 'S',
-1700: 'P',
-500: 'P',
700: 'P',
1900: 'P',
3100: 'P',
-2100: 'G2',
-900: 'G2',
300: 'G2',
1500: 'G2',
2700: 'G2',
-1900: 'M1',
-700: 'M1',
500: 'M1',
1700: 'M1',
2900: 'M1',
-1400: 'N2',
-200: 'N2',
1000: 'N2',
2200: 'N2',
3400: 'N2',
-1500: 'D2',
-300: 'D2',
900: 'D2',
2100: 'D2',
3300: 'D2',
-2200: 'R2',
-1000: 'R2',
200: 'R2',
1400: 'R2',
2600: 'R2'}
Passing the tonic returns these pitches in Hz, else they are returned in cents:
svara_pitch = get_svara_pitch_carnatic('ritigowla', tonic=tonic)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In [20], line 1
----> 1 svara_pitch = get_svara_pitch_carnatic('ritigowla', tonic=tonic)
File /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages/compiam/utils/__init__.py:122, in get_svara_pitch_carnatic(raga, tonic)
121 def get_svara_pitch_carnatic(raga, tonic=None):
--> 122 svara_pitch = get_svara_pitch(
123 raga, tonic, svara_cents_carnatic_path, svara_lookup_carnatic_path
124 )
125 return svara_pitch
File /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages/compiam/utils/__init__.py:138, in get_svara_pitch(raga, tonic, svara_cents_path, svara_lookup_path)
136 if close:
137 error_message += f" Nearest matches: {close}"
--> 138 raise ValueError(error_message)
140 arohana = svara_lookup[raga]["arohana"]
141 avorohana = svara_lookup[raga]["avorohana"]
ValueError: Raga, ritigowla not available in conf. Nearest matches: ['ritigaula']
svara_pitch
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In [21], line 1
----> 1 svara_pitch
NameError: name 'svara_pitch' is not defined
plot_pitch accepts alternative y ticks in the format y-values:label.
plot_pitch(this_pitch, this_time, mask=silence_mask, tonic=tonic, yticks_dict=svara_pitch, cents=True, title='Excerpt of Koti Jamani by The Akkarai Sisters')
ipy_audio(audio, t1, t2, sr=sr)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In [22], line 1
----> 1 plot_pitch(this_pitch, this_time, mask=silence_mask, tonic=tonic, yticks_dict=svara_pitch, cents=True, title='Excerpt of Koti Jamani by The Akkarai Sisters')
2 ipy_audio(audio, t1, t2, sr=sr)
NameError: name 'svara_pitch' is not defined
It should be noted that Carnatic music does not use the equal tempered scale, and indeed that the same svara position, e.g., R2, may be deliberately placed slightly differently in different ragas. Therefore, any deviation here from those theoretical pitch positions does not indicate an error in intonation, but more likely reflects correct musical practice in the style or slight errors in the automated calculation of the tonic.
3. Melodic pattern analysis#
Another important feature of the style is the structural and expressive significance of motifs and phrases known as sañcāras, which can be defined as coherent segments of melodic movement that follow the grammar of the rāga [Pes09, Vis77]. These melodic patterns are the means through which the character of the rāga is expressed and form the basis of various improvisatory and compositional formats in the style [IDBM13, Vis77]. There exists no definitive lists of all possible sañcāras in each rāga, rather the body of existing compositions and the living oral tradition of rāga performance act as repositories for that knowledge [NPRPS22a].
Certain characteristics of Carnatic Music (some of which it shares with many traditions around the world) make the task of identifying repeated motifs and phrases in Carnatic music performances particuarly difficult, particularly in how certain motifs and phrases are often performed across occurrences with variations in tempo, pitch and ornamentation.
We return to Koti Janmani for the pattern analysis.
from compiam.utils.pitch import pitch_seq_to_cents
pitch_cents = pitch_seq_to_cents(pitch, tonic=tonic)
3.1 Melodic feature extraction#
To identify repeated melodic patterns in our audio we use melodic features computed for windows across the entirety of the track and use the pairwise similarity between these to identify regions of consistent high-similarity… in theory corresponding to melodic repetitions.
In principle, any set of features can be used in this section. The extent to which these features capture the aspects of melody we care about will define their usefulness for the task.
Here we use melodic features extracted using a Complex Autoencoder (CAE). Mapping signals onto complex basis functions learnt by the CAE results in a magnitude space that has proven to achieve state-of-the-art results in repeared section discovery for audio [LAD19].
The CAE we use here is provided via compiam.load_models and has been trained on the entirety of the Carnatic Saraga dataset for which we have multitrack recordings.
# Pattern Extraction for a Given Audio
from compiam import load_model
# Feature Extraction
# CAE features
cae = load_model("melody:cae-carnatic")
Extracting features across the entirety of our chosen audio…
# returns magnitude and phase
ampl, _ = cae.extract_features(audio_path)
ampl
[2026-02-18 11:52:34,136] INFO [compiam.melody.pattern.sancara_search.complex_auto.cqt.load_audio:44] loading file ../audio/pattern_finding/Koti Janmani.multitrack-vocal.mp3
tensor([[0.6483, 1.1698, 0.7740, ..., 0.2975, 0.2547, 0.9335],
[0.7594, 0.8208, 0.8685, ..., 0.3448, 0.3398, 0.8742],
[0.7494, 0.5460, 0.7299, ..., 0.1571, 0.2270, 1.0025],
...,
[1.2571, 1.0503, 0.1269, ..., 0.4533, 0.5416, 1.1227],
[0.8959, 0.9634, 0.1403, ..., 0.3993, 0.4328, 1.1705],
[1.2381, 0.8460, 0.1922, ..., 0.2612, 0.3380, 1.0583]],
grad_fn=<PowBackward0>)
3.2 Self similarity#
We want to compute the pairwsie self similarity between all combinations of features. With some Carnatic performances lasting up to over an hour, this can often be an expensive computation. There are many regions of the track that we are not interested in (such as silence), or that serve as plausible segmentation points for repeated melodic patterns (such as long periods of stability/silence).
compiam.melody.pattern.self_similarity provides a method of computing the self similarity whilst skipping the computation for regions defined by a user specified exclusion mask.
from compiam.melody.pattern import self_similarity
First let’s compute the mask corresponding to regions we do not want to compute, these are regions of silence:
silence_mask = pitch==0
And regions of consistent stability. To identify regions of consistent stability we use compiam.utils.pitch.extract_stability_mask. extract_stability_mask computes the average deviation of pitch from the mean in a series of windows across the track. If the deviation exceeds a certain threshold for a sufficient number of consecutive windows, the area is marked as stable (1 in the returned mask), else 0.
from compiam.utils.pitch import extract_stability_mask
stability_mask = extract_stability_mask(
pitch=pitch_cents, # pitch track
min_stab_sec=1.0, # minimum cummulative length of stable windows to warrant annotation
hop_sec=0.2, # hop length in seconds
var=60, # minimum variation from the mean in each window to be considered stable
timestep=timestep # time in seconds between consecutice elements in <pitch>
)
We can inspect the result to check it has worked correctly
t1 = 304 # in seconds
t2 = t1 + 10 # in seconds
t1s = round(t1/timestep) # in sequence elements
t2s = round(t2/timestep) # in sequence elements
this_pitch = pitch[t1s:t2s]
this_time = time[t1s:t2s]
this_silence_mask = silence_mask[t1s:t2s]
this_stable_mask = stability_mask[t1s:t2s]
# get pitch plot
fig, ax = plot_pitch(this_pitch, this_time, mask=this_silence_mask, tonic=tonic, yticks_dict=svara_pitch, cents=True, title='Excerpt of Koti Jamani by The Akkarai Sisters')
# On alternative axis plot stable mask values
ax2 = ax.twinx()
ax2.plot(this_time, this_stable_mask, 'g', linewidth=1, alpha=1, linestyle='--')
ax2.set_yticks([0,1])
ax2.set_ylabel("Is stable region?")
# accompanying audio
ipy_audio(audio, t1, t2, sr=sr)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In [31], line 13
10 this_stable_mask = stability_mask[t1s:t2s]
12 # get pitch plot
---> 13 fig, ax = plot_pitch(this_pitch, this_time, mask=this_silence_mask, tonic=tonic, yticks_dict=svara_pitch, cents=True, title='Excerpt of Koti Jamani by The Akkarai Sisters')
15 # On alternative axis plot stable mask values
16 ax2 = ax.twinx()
NameError: name 'svara_pitch' is not defined
Here the green line is to be read from the right-hand y-axis… is the region stable or not?
Looks good! Let’s combine the two masks:
import numpy as np
exclusion_mask = np.logical_or(silence_mask==1, stability_mask==1)
And compute the self similarity self_similarity():
# Mask of regions not interested in cite kaustuv, the papers that use
ss = self_similarity(
ampl, # features
exclusion_mask=exclusion_mask, # exclusion mask
timestep=timestep, # time in seconds between elements of exlcusion mask
hop_length=cae.hop_length, # window size in audio frames
sr=cae.sr # sample rate of audio
)
# Sparsely computed self similarity matrix
X = ss[0]
# Mapping of index between theoretical full matrix and sparse one
orig_sparse_lookup = ss[1]
# Mapping of index between sparse matrix and theoretical full matrix one
sparse_orig_lookup = ss[2]
# Indices of boundaries between split regions in full matrix
boundaries_orig = ss[3]
# Indices of boundaries between split regions in sparse matrix
boundaries_sparse = ss[4]
How does the self similarity matrix look?
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10,10))
plt.title(f'Self similarity matrix for Koti Janmani', fontsize=9)
ax.imshow(X[2000:5000,2000:5000], interpolation='nearest')
plt.axis('off')
plt.tight_layout()
plt.show()

3.3 Segment extraction#
Diagonal segments in this self similarity matrix correspond to two regions of consistent high similarity (one on the x axis and y axis). We want to extract and define these segments.
Instances of the same sañcāra are often performed slightly differently. Tempo differences mean that the segments cannot be expected to be parallel to the y=x diagonal. Differences in ornamention or differences in elaboration (such as the insertion of additional svaras or gamakas) mean that segments are sometimes not completely consistent unbroken lines, terminating and ending at exactly the same place.
To deal with extraction in this context we use the segment extractor at compiam.melody.pattern.segmentExtractor which is adapted from [NPRPS22a] and built specifically for the Carnatic Music context.
from compiam.melody.pattern import segmentExtractor
# Emphasize Diagonal
se = segmentExtractor(
X, # self sim matrix
window_size=cae.hop_length, # window size
cache_dir='.cache/' # cache directory for faster computation in future
)
First we emphasize existing segments using a series of image processing techiniques:
Convolution with a sobel filter to emphasize edges
Normalise similarities to between 1 and 0
Binarize matrix to 0/1 above or below some threshold
Since the emphasized edges correspond to the borders of the segment and not the segment itself we apply morphological closing to fill gaps
Finally we apply morphological closing to smooth and remove noisy artifacts

X_proc = se.emphasize_diagonals()
se.display_matrix(X_proc)
We can tune parameters visually using the se.display_matrix to view the processed plot. One of the most important parameters is the binary threshold, bin_thresh. Let’s iterate through a sample and choose one that balances noise and segment integrity.
for i in np.arange(0.05, 0.15, 0.01):
X_proc = se.emphasize_diagonals(bin_thresh=i)
se.display_matrix(X_proc[2000:5000,2000:5000], title=f'bin_thresh={round(i,2)}', figsize=(5,5))










We are looking for a solution that reduces the “speccy” noise parts and leaves strong, consistent diagonal segments. 0.1 seems like an OK choice.
X_proc = se.emphasize_diagonals(bin_thresh=0.1)
Finally we extract segments using a combination of geometric techniques:
Identify individual regions of non 0 values using a two-pass binary connected-components labelling algorithm (CCL)
Identify centroid of region
Idenitfy quadrant centroids
Define path through these centroids using least squares
Terminate path at bounding box of segment
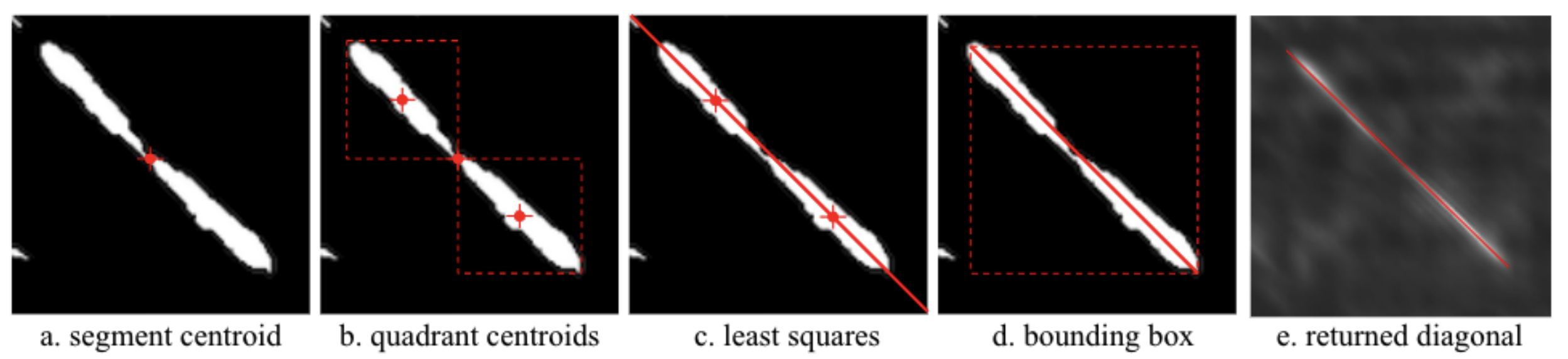
Note: All identified segments are compared to each other, as such this step may take some time to run for long performances with many segments/repetitions. The intermediate processed data is cached in the above cache directory and hence for the same parameters should run immediately in future.
all_segments = se.extract_segments(
timestep=timestep, # timestep between
boundaries=boundaries_sparse, # boundaries of sparse regions (for conversion)
lookup=sparse_orig_lookup, # To convert between sparse and true indices
break_mask=exclusion_mask) # mask corresponding to break points, any segment that traverse these points are broken into two
print("Format: [(x0, y0), (x1, y1)]...")
all_segments[:10]
Format: [(x0, y0), (x1, y1)]...
[[(128, 136), (173, 182)],
[(136, 128), (181, 174)],
[(276, 285), (347, 356)],
[(283, 276), (355, 348)],
[(477, 486), (542, 551)],
[(484, 477), (551, 543)],
[(597, 606), (758, 767)],
[(604, 597), (767, 759)],
[(655, 689), (719, 734)],
[(689, 655), (734, 719)]]
3.4 Segment grouping#
Each segment corresponds to two regions of the audio, one on the x axis and one on the y axis. We want to convert these segments to start and end points of individual patterns and group these patterns into groups of occurrences of the same pattern.
segmentExtractor has a grouping method which achieves this using a combination of the gemoetry of X and pairwise distances between patterns. First segments are grouped based on their alignment in the x and y direction. Subsequently, groups are merged together based on the average dynamic-time-warping distance between them. It is worth noting that DTW grouping is quite resource intensive, you can optionally turn it off by passing the parameter thresh_dtw=None to group_segments.
A mask corresponding to anchor points to which we might want to extent returned patterns to can be passed to segmentExtractor.group_segments and any patterns that end or begin close to these points will be extended to them. Since regions of silence and stability serve as plasusible segmentation points between patterns we pass a mask indicating where the centers are for these regions.
from compiam.utils import add_center_to_mask
exclusion_mask_center = add_center_to_mask(exclusion_mask) # center of masked regions is annotated as "2"
anchor_mask = np.array([1 if i==2 else 0 for i in exclusion_mask_center])
# Returns patterns in units of pitch sequence elements
starts_seq, lengths_seq = se.group_segments(
all_segments, # segments from se.extract_segments()
anchor_mask, # Extend patterns to these points
pitch, # pitch track
min_pattern_length_seconds=2, # minimum pattern length,
thresh_dtw=None
)
The process returns groups of patterns in terms of start point and length. The units for these patterns correspond to elements in the pitch track. We can convert to seconds as so:
starts_sec = [[x*timestep for x in p] for p in starts_seq]
lengths_sec = [[x*timestep for x in l] for l in lengths_seq]
print(f"Number of groups: {len(starts_sec)}")
Number of groups: 36
3.5 Exploring results#
Let’s take a look at some results. compiam.visualisation.pitch.plot_subsequence is a wrapper forcompiam.visualisation.pitch.plot_pitch that allows us to inspect subsequences of a pitch plot with their surrounding melodic context.
from compiam.visualisation.pitch import plot_subsequence
import IPython
# kwargs for plot_pitch
plot_kwargs = {
'yticks_dict': svara_pitch,
'cents':True,
'tonic':tonic,
'figsize':(15,4)
}
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In [49], line 3
1 # kwargs for plot_pitch
2 plot_kwargs = {
----> 3 'yticks_dict': svara_pitch,
4 'cents':True,
5 'tonic':tonic,
6 'figsize':(15,4)
7 }
NameError: name 'svara_pitch' is not defined
i = 6 # Choose pattern group
S = starts_seq[i] # get group
L = lengths_seq[i] # get lengths
for j,s in enumerate(S):
l = L[j] # this pattern length
ss = starts_sec[i][j] # this pattern start in seconds
ls = lengths_sec[i][j] # this pattern length in seconds
IPython.display.display(ipy_audio(audio, ss, ss+ls, sr=sr)) # display audio
# display pitch plot
plot_subsequence(s, l, pitch, time, timestep, path=None, plot_kwargs=plot_kwargs)
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In [50], line 12
10 IPython.display.display(ipy_audio(audio, ss, ss+ls, sr=sr)) # display audio
11 # display pitch plot
---> 12 plot_subsequence(s, l, pitch, time, timestep, path=None, plot_kwargs=plot_kwargs)
13 plt.show()
NameError: name 'plot_kwargs' is not defined