Music segmentation#
We have seen in the musicological introduction that we may come across different formats of Carnatic and Hindustani performances. Let us review some example works that have been proposed for this task. [VVPR15] proposes to use tempo cues combined with additional handcrafted features that aim at capturing tradition-relevant information. On the other hand, [RPS19] quantize the pitch contours, identify repeated note sequences or patterns, and then compute posterior probabilities to identify the different sections. Alternatively, [GGSR16] builds on top of hand-crafted features of pitch time-series. Finally, DL models are also used to identify the meter and tempo surfaces of Dhrupad Bandish performances for segmentation [MAVR20].
## Installing (if not) and importing compiam to the project
import importlib.util
if importlib.util.find_spec('compiam') is None:
## Bear in mind this will only run in a jupyter notebook / Collab session
%pip install git+git://github.com/MTG/compIAM.git
import compiam
# Import extras and supress warnings to keep the tutorial clean
import os
from pprint import pprint
import warnings
warnings.filterwarnings('ignore')
Let’s first list the available tools for music segmentation in compiam.
compiam.structure.segmentation.list_tools()
['DhrupadBandishSegmentation*']
Dhrupad Bandish segmentation#
In this section we will showcase a tool that attempts to identify, through the use of rhythmic features, different sections in a Dhrupad Bandish performances [MAVR20], one of the main formats in Hindustani music. As seen in the documentation, this segmentation model is based on PyTorch. Therefore, we proceed to install torch.
%pip install torch==1.13.0
This tool may be accessed from the structure.segmentation, however, the tool name has an * appended, therefore we can use the wrapper for models to rapidly initialize it with the pre-trained weights loaded.
Tip
Get the correct identifier for the wrapper by running compiam.list_models().
dbs = compiam.load_model("structure:dhrupad-bandish-segmentation")
help(dbs)
Help on DhrupadBandishSegmentation in module compiam.structure.segmentation.dhrupad_bandish_segmentation object:
class DhrupadBandishSegmentation(builtins.object)
| DhrupadBandishSegmentation(mode='net', fold=0, model_path=None, splits_path=None, annotations_path=None, features_path=None, original_audios_path=None, processed_audios_path=None, download_link=None, download_checksum=None, device=None)
|
| Dhrupad Bandish Segmentation
|
| Methods defined here:
|
| __init__(self, mode='net', fold=0, model_path=None, splits_path=None, annotations_path=None, features_path=None, original_audios_path=None, processed_audios_path=None, download_link=None, download_checksum=None, device=None)
| Dhrupad Bandish Segmentation init method.
|
| :param mode: net, voc, or pakh. That indicates the source for s.t.m. estimation. Use the net
| mode if audio is a mixture signal, else use voc or pakh for clean/source-separated vocals or
| pakhawaj tracks.
| :param fold: 0, 1 or 2, it is the validation fold to use during training.
| :param model_path: path to file to the model weights.
| :param splits_path: path to file to audio splits.
| :param annotations_path: path to file to the annotations.
| :param features_path: path to file to the computed features.
| :param original_audios_path: path to file to the original audios from the dataset (see README.md in
| compIAM/models/structure/dhrupad_bandish_segmentation/audio_original)
| :param processed_audios_path: path to file to the processed audio files.
| :param download_link: link to the remote pre-trained model.
| :param download_checksum: checksum of the model file.
| :param device: indicate whether the model will run on the GPU.
|
| download_model(self, model_path=None, force_overwrite=False)
| Download pre-trained model.
|
| load_model(self, model_path)
| Loading weights for model, given self.mode and self.fold
|
| :param model_path: path to model weights
|
| predict_stm(self, input_data, input_sr=44100, save_output=False, output_path=None)
| Predict Dhrupad Bandish Segmentation
|
| :param input_data: path to audio file or numpy array like audio signal.
| :param input_sr: sampling rate of the input array of data (if any). This variable is only
| relevant if the input is an array of data instead of a filepath.
| :param save_output: boolean indicating whether the output figure for the estimation is
| stored.
| :param output_path: if the input is an array, and the user wants to save the estimation,
| the output_path must be provided, path/to/picture.png.
|
| train(self, verbose=True)
| Train the Dhrupad Bandish Segmentation model
|
| :param verbose: showing details of the model
|
| update_fold(self, fold)
| Update data fold for the training and sampling
|
| :param fold: new fold to use
|
| update_mode(self, mode)
| Update mode for the training and sampling. Mode is one of net, voc,
| pakh, indicating the source for s.t.m. estimation. Use the net mode if
| audio is a mixture signal, else use voc or pakh for clean/source-separated
| vocals or pakhawaj tracks.
|
| :param mode: new mode to use
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables
|
| __weakref__
| list of weak references to the object
In the documentation we observe that this model includes quite a number of attributes, and particularly we observe two of them that are interesting:
modefold
These attributes are important because define the training pipeline that has been used and therefore, a different mode of operating with this model. mode has options: net, voc, or pakh, which indicate the source for surface tempo multiple (s.t.m.) estimation. net mode is for input mixture signal, voc is for clean or source-separated singing voice recordings, and pakh for pakhawaj tracks (pakhawaj is a percussion instrument from Northern India). fold is basically an integer indicating with validation fold we do consider for training.
These configuration variables are loaded by default as net and 0 respectively, however these may be easily changed.
dbs.update_mode(mode="voc")
dbs.update_fold(fold=1)
At this moment, the mode and fold have been updated and consequently, the class has automatically loaded the model weights corresponding to mode=voc and fold=1.
Note
Typically in compiam, importing a model from the corresponding module or initializing it using the wrapper, can make an important difference on how the loaded instance works. Generally speaking, if you use the wrapper you will probably be only interested in running inference. If your goal is to train or deep-dive into a particular model, you should avoid the use of the model wrapper and start from a clean model instance.
Let’s now run prediction on an input file. Our mode now is voc, therefore the model expects a clean or source separated vocal signal. Isolated singing voice signals are not commonly available for the case of Carnatic and Hindustani music. We will use a state-of-the-art and out-of-the-box model, spleeter, to try to separate the singing voice from the accompaniment.
%pip install spleeter
%pip install "keras<3"
Requirement already satisfied: spleeter in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (2.4.2)
Requirement already satisfied: ffmpeg-python<0.3.0,>=0.2.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from spleeter) (0.2.0)
Requirement already satisfied: httpx<0.20.0,>=0.19.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from httpx[http2]<0.20.0,>=0.19.0->spleeter) (0.19.0)
Requirement already satisfied: norbert<0.3.0,>=0.2.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from spleeter) (0.2.1)
Requirement already satisfied: numpy<2.0.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from spleeter) (1.24.3)
Requirement already satisfied: pandas<2.0.0,>=1.3.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from spleeter) (1.5.3)
Collecting tensorflow==2.12.1 (from spleeter)
Using cached tensorflow-2.12.1-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (3.4 kB)
Requirement already satisfied: tensorflow-io-gcs-filesystem==0.32.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from spleeter) (0.32.0)
Requirement already satisfied: typer<0.4.0,>=0.3.2 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from spleeter) (0.3.2)
Requirement already satisfied: absl-py>=1.0.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (2.4.0)
Requirement already satisfied: astunparse>=1.6.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (1.6.3)
Requirement already satisfied: flatbuffers>=2.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (25.12.19)
Requirement already satisfied: gast<=0.4.0,>=0.2.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (0.4.0)
Requirement already satisfied: google-pasta>=0.1.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (0.2.0)
Requirement already satisfied: grpcio<2.0,>=1.24.3 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (1.74.0)
Requirement already satisfied: h5py>=2.9.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (3.15.1)
Requirement already satisfied: jax>=0.3.15 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (0.4.38)
Collecting keras<2.13,>=2.12.0 (from tensorflow==2.12.1->spleeter)
Using cached keras-2.12.0-py2.py3-none-any.whl.metadata (1.4 kB)
Requirement already satisfied: libclang>=13.0.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (18.1.1)
Requirement already satisfied: opt-einsum>=2.3.2 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (3.4.0)
Requirement already satisfied: packaging in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (26.0)
Requirement already satisfied: protobuf!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<5.0.0dev,>=3.20.3 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (4.25.8)
Requirement already satisfied: setuptools in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (79.0.1)
Requirement already satisfied: six>=1.12.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (1.17.0)
Collecting tensorboard<2.13,>=2.12 (from tensorflow==2.12.1->spleeter)
Using cached tensorboard-2.12.3-py3-none-any.whl.metadata (1.8 kB)
Collecting tensorflow-estimator<2.13,>=2.12.0 (from tensorflow==2.12.1->spleeter)
Using cached tensorflow_estimator-2.12.0-py2.py3-none-any.whl.metadata (1.3 kB)
Requirement already satisfied: termcolor>=1.1.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (3.3.0)
Requirement already satisfied: typing-extensions<4.6.0,>=3.6.6 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (4.5.0)
Requirement already satisfied: wrapt<1.15,>=1.11.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorflow==2.12.1->spleeter) (1.14.2)
Requirement already satisfied: future in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from ffmpeg-python<0.3.0,>=0.2.0->spleeter) (1.0.0)
Requirement already satisfied: certifi in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from httpx<0.20.0,>=0.19.0->httpx[http2]<0.20.0,>=0.19.0->spleeter) (2026.1.4)
Requirement already satisfied: charset-normalizer in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from httpx<0.20.0,>=0.19.0->httpx[http2]<0.20.0,>=0.19.0->spleeter) (3.4.4)
Requirement already satisfied: sniffio in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from httpx<0.20.0,>=0.19.0->httpx[http2]<0.20.0,>=0.19.0->spleeter) (1.3.1)
Requirement already satisfied: rfc3986<2,>=1.3 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from rfc3986[idna2008]<2,>=1.3->httpx<0.20.0,>=0.19.0->httpx[http2]<0.20.0,>=0.19.0->spleeter) (1.5.0)
Requirement already satisfied: httpcore<0.14.0,>=0.13.3 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from httpx<0.20.0,>=0.19.0->httpx[http2]<0.20.0,>=0.19.0->spleeter) (0.13.7)
Requirement already satisfied: h11<0.13,>=0.11 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from httpcore<0.14.0,>=0.13.3->httpx<0.20.0,>=0.19.0->httpx[http2]<0.20.0,>=0.19.0->spleeter) (0.12.0)
Requirement already satisfied: anyio==3.* in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from httpcore<0.14.0,>=0.13.3->httpx<0.20.0,>=0.19.0->httpx[http2]<0.20.0,>=0.19.0->spleeter) (3.7.1)
Requirement already satisfied: idna>=2.8 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from anyio==3.*->httpcore<0.14.0,>=0.13.3->httpx<0.20.0,>=0.19.0->httpx[http2]<0.20.0,>=0.19.0->spleeter) (3.11)
Requirement already satisfied: h2<5,>=3 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from httpx[http2]<0.20.0,>=0.19.0->spleeter) (4.3.0)
Requirement already satisfied: hyperframe<7,>=6.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from h2<5,>=3->httpx[http2]<0.20.0,>=0.19.0->spleeter) (6.1.0)
Requirement already satisfied: hpack<5,>=4.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from h2<5,>=3->httpx[http2]<0.20.0,>=0.19.0->spleeter) (4.1.0)
Requirement already satisfied: scipy in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from norbert<0.3.0,>=0.2.1->spleeter) (1.15.3)
Requirement already satisfied: python-dateutil>=2.8.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from pandas<2.0.0,>=1.3.0->spleeter) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from pandas<2.0.0,>=1.3.0->spleeter) (2025.2)
Requirement already satisfied: google-auth<3,>=1.6.3 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (2.48.0)
Requirement already satisfied: google-auth-oauthlib<1.1,>=0.5 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (1.0.0)
Requirement already satisfied: markdown>=2.6.8 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (3.10.2)
Requirement already satisfied: requests<3,>=2.21.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (2.32.5)
Requirement already satisfied: tensorboard-data-server<0.8.0,>=0.7.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (0.7.2)
Requirement already satisfied: werkzeug>=1.0.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (3.1.5)
Requirement already satisfied: wheel>=0.26 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (0.46.3)
Requirement already satisfied: pyasn1-modules>=0.2.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (0.4.2)
Requirement already satisfied: cryptography>=38.0.3 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (46.0.5)
Requirement already satisfied: rsa<5,>=3.1.4 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (4.9.1)
Requirement already satisfied: requests-oauthlib>=0.7.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from google-auth-oauthlib<1.1,>=0.5->tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (2.0.0)
Requirement already satisfied: urllib3<3,>=1.21.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from requests<3,>=2.21.0->tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (2.6.3)
Requirement already satisfied: pyasn1>=0.1.3 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from rsa<5,>=3.1.4->google-auth<3,>=1.6.3->tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (0.6.2)
Requirement already satisfied: click<7.2.0,>=7.1.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from typer<0.4.0,>=0.3.2->spleeter) (7.1.2)
Requirement already satisfied: cffi>=2.0.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from cryptography>=38.0.3->google-auth<3,>=1.6.3->tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (2.0.0)
Requirement already satisfied: pycparser in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from cffi>=2.0.0->cryptography>=38.0.3->google-auth<3,>=1.6.3->tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (3.0)
Requirement already satisfied: jaxlib<=0.4.38,>=0.4.38 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from jax>=0.3.15->tensorflow==2.12.1->spleeter) (0.4.38)
Collecting ml_dtypes>=0.4.0 (from jax>=0.3.15->tensorflow==2.12.1->spleeter)
Using cached ml_dtypes-0.5.4-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.metadata (8.9 kB)
Requirement already satisfied: oauthlib>=3.0.0 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<1.1,>=0.5->tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (3.3.1)
Requirement already satisfied: markupsafe>=2.1.1 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (from werkzeug>=1.0.1->tensorboard<2.13,>=2.12->tensorflow==2.12.1->spleeter) (3.0.3)
Using cached tensorflow-2.12.1-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (585.9 MB)
Using cached keras-2.12.0-py2.py3-none-any.whl (1.7 MB)
Using cached tensorboard-2.12.3-py3-none-any.whl (5.6 MB)
Using cached tensorflow_estimator-2.12.0-py2.py3-none-any.whl (440 kB)
Using cached ml_dtypes-0.5.4-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl (5.0 MB)
Installing collected packages: tensorflow-estimator, ml_dtypes, keras, tensorboard, tensorflow
?25l
Attempting uninstall: tensorflow-estimator
Found existing installation: tensorflow-estimator 2.15.0
Uninstalling tensorflow-estimator-2.15.0:
Successfully uninstalled tensorflow-estimator-2.15.0
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0/5 [tensorflow-estimator]
Attempting uninstall: ml_dtypes
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0/5 [tensorflow-estimator]
Found existing installation: ml-dtypes 0.2.0
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0/5 [tensorflow-estimator]
Uninstalling ml-dtypes-0.2.0:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0/5 [tensorflow-estimator]
Successfully uninstalled ml-dtypes-0.2.0
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0/5 [tensorflow-estimator]
━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1/5 [ml_dtypes]
Attempting uninstall: keras
━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1/5 [ml_dtypes]
Found existing installation: keras 2.15.0
━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1/5 [ml_dtypes]
Uninstalling keras-2.15.0:
━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1/5 [ml_dtypes]
Successfully uninstalled keras-2.15.0
━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1/5 [ml_dtypes]
━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━ 2/5 [keras]
━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━ 2/5 [keras]
━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━ 2/5 [keras]
━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━ 2/5 [keras]
━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━ 2/5 [keras]
━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━ 2/5 [keras]
Attempting uninstall: tensorboard
━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━ 2/5 [keras]
Found existing installation: tensorboard 2.15.2
━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━ 2/5 [keras]
Uninstalling tensorboard-2.15.2:
━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━ 2/5 [keras]
Successfully uninstalled tensorboard-2.15.2
━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━ 2/5 [keras]
━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━ 3/5 [tensorboard]
━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━ 3/5 [tensorboard]
Attempting uninstall: tensorflow
━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━ 3/5 [tensorboard]
Found existing installation: tensorflow 2.15.0
━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━ 3/5 [tensorboard]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
Uninstalling tensorflow-2.15.0:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
Successfully uninstalled tensorflow-2.15.0
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 4/5 [tensorflow]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5/5 [tensorflow]
?25h
Successfully installed keras-2.12.0 ml_dtypes-0.5.4 tensorboard-2.12.3 tensorflow-2.12.1 tensorflow-estimator-2.12.0
Note: you may need to restart the kernel to use updated packages.
Requirement already satisfied: keras<3 in /opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages (2.12.0)
Note: you may need to restart the kernel to use updated packages.
We will now directly download the pre-trained models for spleeter, and use these for inference in this walkthrough. We will use wget (UNIX-based) to download the available pre-trained weights for spleeter online.
!wget https://github.com/deezer/spleeter/releases/download/v1.4.0/2stems.tar.gz
We need to use tarfile to uncompress the downloaded file into a desired location. We will uncompres the downloaded model weights to the default location where spleeter looks for the pretrained weights.
import tarfile
# Open file
file = tarfile.open("2stems.tar.gz")
# Creating directory where spleeter looks for models by default
os.mkdir("pretrained_models/")
# Extracting files in tar
file.extractall(
os.path.join("pretrained_models", "2stems")
)
# Closing file
file.close()
spleeter is based on TensorFlow. We disable the GPU usage and the TensorFlow related warnings just like we did in the pitch extraction walkthrough.
# Disabling tensorflow warnings and debugging info
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
# Importing tensorflow and disabling GPU usage
import tensorflow as tf
tf.config.set_visible_devices([], "GPU")
We may now load the spleeter separator, which will automatically load the pre-trained weights for the model. We will use the 2:stems model, which has been trained to separate vocals and accompaniment.
Note
The other option, which is the 4:stems, separates vocals, bass, drums, and other.
import spleeter
from spleeter.separator import Separator
# Load default 2-stem spleeter separation
separator = Separator("spleeter:2stems")
The Separator class in spleeter has a method to directly separate the singing voice from an audio file, and the prediction is stored in a given output folder. Let’s use this method and get a source separated version of an example Dhrupad file.
pprint(compiam.list_datasets())
['saraga_carnatic',
'saraga_hindustani',
'mridangam_stroke',
'four_way_tabla',
'compmusic_carnatic_rhythm',
'compmusic_hindustani_rhythm',
'compmusic_raga',
'compmusic_indian_tonic',
'compmusic_carnatic_varnam',
'scms']
Oops… We note that no Dhrupad Bandish dataset is available in mirdata. Therefore, we will need to refer to the Carnatic and Hindustani corpora in Dunya. Let’s get an audio example from Dunya using the Corpora class. As already mentioned before, you need a personal and non-shareable token to access the data in Dunya. Within the context of this tutorial, we provide here a snippet of code that we have used beforehand to parse the audios from the Dunya database.
If we the folder compiam/models/structure/dhrupad_bandish_segmentation/audio_original within the installable compiam. We can see a .pdf file including the details of the files that form the dataset for the Dhrupad Segmentation tool. That .pdf file is also found in the original repository of the tool. We select the following example:
# UNCOMMENT AND RUN THIS CODE WITH YOUR PERSONAL TOKEN
#from compiam import load_corpora
#corpora = load_corpora(
# "hindustani",
# cc=False, # Indicating we import de private collection
# token="<your-access-token>",
#
#corpora.download_mp3(
# "59c88c32-0bde-433b-b194-0f65281e5714",
# "os.path.join("..", "audio")
#)
Let’s make sure the audios are actually downloaded in the audio folder.
%ls ../audio
59c88c32-0bde-433b-b194-0f65281e5714.mp3 mir_datasets/ separation/
demos/ pattern_finding/ testing_samples/
Cool! There it is. Let’s therefore now run the spleeter separation on this track.
# Separating file
separator.separate_to_file(
os.path.join(
"..", "audio", "59c88c32-0bde-433b-b194-0f65281e5714.mp3"
),
os.path.join("..", "audio")
)
Separation done! We can now run inference with the segmentation model on the source separated signal.
dbs.predict_stm(
input_data=os.path.join(
"..", "audio", "59c88c32-0bde-433b-b194-0f65281e5714.mp3"
)
)
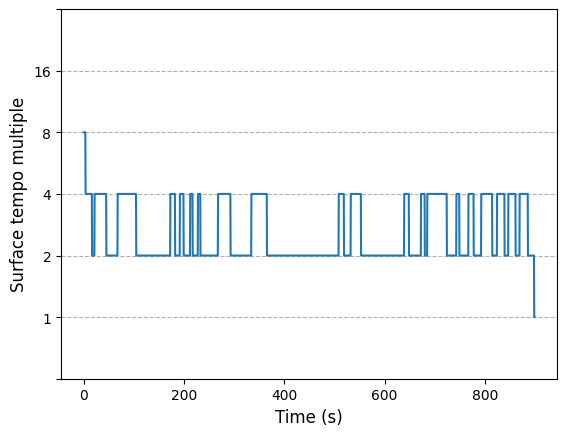
array([3, 3, 3, ..., 1, 0, 0])
We can observe the estimated sections (given rhythmic characteristics) in the output image. The x axis provides information about the actual time-stamps in seconds for each estimation.
As a final experiment, let’s listen to the source separated file using spleeter.
import IPython.display as ipd
import librosa
vocals, sr = librosa.load(
os.path.join(
"..", "audio", "59c88c32-0bde-433b-b194-0f65281e5714.mp3"
),
)
ipd.Audio(
data=vocals[-sr*30:], # Taking only the last 30 seconds
rate=sr,
)
A note on source separation for Indian Art Music#
As you may have noticed in the displayed audio above, even though spleeter is within the best out-of-the-box source separation models to use, we need to take into account some considerations in regards to the task of music source separation for Indian Art Music signals.
First of all, although spleeter is trained with a massive amount of recordings, we can safely assume that Carnatic and Hindustani music do not have a considerable representation in the training set (this applies to the other out-of-the-box source separation models out there). In that sense, it is expected that these models struggle to generalize to Indian Art Music specific instruments and arrangements, which may cause abnormally low interference removal performance. The predominance of melodic monophonic accompaniment instruments in both Carnatic (the violin being the most common case) and Hindustani (harmonium in this case), the tambura drone, the pitched percussion… These are high-level examples of elements that may cause the standardized source separation models to not generalize properly to Indian Art Music signals.
What is more, the standardized source separation models target whether vocals and accompaniment, or vocals, bass, drums, and other. While to separate the singing voice from an accompaniment is OK, the 4 stem configuration is far from being representative of the actual Carnatic and Hindustani Music arrangements.
As a final note, another factor that is currently blocking the research on music source separation for Indian Art Music is the shortage of available datasets for this task. We have observed that the Saraga Carnatic collection has multi-track audio, but this has leakage (it has been recorded in live performances). In such case, a leakage-aware approach would be needed to use this data. Alternatively, a music source separation dataset including completely isolated and aligned tracks, which to the best of our knowledge is unavailable as of now, would open the door the music source separation research on Indian Art Music.
Nov 2023 Update: A Carnatic-specific singing voice separation model has been developed and presented at ISMIR 2023 in Milan, Italy. See the separation walkthrough for an example.