compIAM package#
This tutorial built around the compIAM package (computational analysis of Indian Art Music, and programatically stylized as compiam), which is a collaborative initiative involving many researchers that aims to put together a common repository of datasets, tools, and models for the computational analysis of Carnatic and Hindustani music.
Motivation#
Tons of very interesting and useful works have been carried out within the topic of computational analysis of Carnatic and Hindustani Music. However, it is common to come across, in such research contexts, difficulties and problems in finding or reproducing the published research.
compiam aims to be a common and community-driven repository including Python-based and standardized implementations of research works for the computational analysis of IAM. In addition, compiam includes tools to easily access relevant datasets and corpora.
Note
compiam is very open to contributions! To integrate your works or relevant implementations from other researchers please check out the contributing guidelines.
Installation#
compiam is registered to PyPI, therefore the latest release can be installed with:
pip install compiam
Nonetheless, to get the latest version of the library with the fresher updates, proceed as follows:
git clone https://github.com/MTG/compIAM.git
cd compIAM
virtualenv -p python3 compiam_env
source compiam_env/bin/activate
pip install -e .
pip install -r requirements.txt
Available components#
compiam includes the following components:
What to load? |
Description |
|---|---|
Datasets |
Initializing dataset loaders through mirdata (see Datasets) |
Corpora (Dunya) |
Accessing the Dunya corpora (see Corpora) |
Tools and models |
Initializing tools and non-pre-trained ML and DL models |
Pre-trained DL models |
Initializing pre-trained models |
Basic usage#
compiam does not have terminal functionalities but it is to be used within Python based-projects. First, import the library to your Python project with:
## Installing (if not) and importing compiam to the project
import importlib.util
if importlib.util.find_spec('compiam') is None:
## Bear in mind this will only run in a jupyter notebook / Collab session
%pip install compiam
import compiam
Reminder
Most likely, after importing a particular notebook of this tutorial to a Google Collab session, compiam will not be installed. On the cell above we first check if compiam is installed and if not, we run the installation command to get the latest version released.
We will import some additional util packages for improved user experience along the tutorial.
import os
import numpy as np
import IPython.display as ipd
from pprint import pprint
import warnings
warnings.filterwarnings('ignore')
Importing the integrated tools#
The integrated tools and models are organized by:
First, the following fundamental musical aspects: melody, rhythm, structure, and timbre.
Within each of the musical aspect, the tools then are grouped by task.
Print out the available tasks for each category.
pprint(compiam.melody.list_tasks())
['pattern', 'pitch_extraction', 'raga_recognition', 'tonic_identification']
You may also print out the available tools for a musical aspect.
pprint(compiam.melody.list_tools())
['pattern.CAEWrapper*',
'extraction.segmentExtractor',
'pitch_extraction.FTANetCarnatic*',
'pitch_extraction.FTAResNetCarnatic*',
'pitch_extraction.Melodia',
'raga_recognition.DEEPSRGM*',
'tonic_identification.TonicIndianMultiPitch']
Finally, you may be only interested on listing only the tools for a particular task.
pprint(compiam.rhythm.transcription.list_tools())
['MnemonicTranscription']
Right, we have now learned how to list the available tools in compiam. Initializing and using the integrated works in compiam can be done by basically importing these from the respective module. Use that to load non-trainable tools and non-trained machine or deep learning (ML/DL) models.
from compiam.melody.tonic_identification import TonicIndianMultiPitch
from compiam.rhythm.meter import AksharaPulseTracker
Each tool includes specific methods and attributes, so make sure to carefully check the compiam documentation before using a particular tool. However, integrated tools all include a .extract() (for heuristic-based tools) or a .predict() (for data-driven tools) to directly run the tool on any input audio.
Wrappers#
compiam also includes wrappers to easily initialize relevant datasets, corpora, and also pre-trained models for particular problems.
Wrapper |
Description |
Option list |
|---|---|---|
|
Initializing dataset loaders |
Run |
|
Accessing the Dunya corpora |
Run |
|
Initializing pre-trained models |
Run |
Why wrappers?#
Wrappers can be directly imported from compiam, and serve as a fast and standardized manner to access the data and pre-trained models in compiam. Let us showcase the nice utility of the compiam wrappers.
from compiam import load_dataset, load_corpora, load_model
The .load_dataset() wrapper#
We will start by listing the available datasets through compiam using the .load_datasets() method which is implemented in the core of compiam.
pprint(compiam.list_datasets())
['saraga_carnatic',
'saraga_hindustani',
'mridangam_stroke',
'four_way_tabla',
'compmusic_carnatic_rhythm',
'compmusic_hindustani_rhythm',
'compmusic_raga',
'compmusic_indian_tonic',
'compmusic_carnatic_varnam',
'scms']
The compiam.load_dataset() wrapper allows the user to initialize the dataloader for any dataset included in the list displayed above.
## Initializing dataloader for an example dataset
saraga_carnatic = load_dataset("saraga_carnatic")
The load_dataset() wrapper automatically downloads the dataset “index”, which is used to build the dataloader, locate the dataset files, and identify each entity in the dataset. For more information on the mechanics of the dataset loading, see the mirdata documentation and the dataset walkthrough of this tutorial.
Let’s now see how the dataset class looks like inside:
saraga_carnatic
The saraga_carnatic dataset
----------------------------------------------------------------------------------------------------
Call the .cite method for bibtex citations.
----------------------------------------------------------------------------------------------------
Saraga Track Carnatic class
Args:
track_id (str): track id of the track
data_home (str): Local path where the dataset is stored. default=None
If `None`, looks for the data in the default directory, `~/mir_datasets`
Attributes:
audio_path (str): path to audio file
audio_ghatam_path (str): path to ghatam audio file
audio_mridangam_left_path (str): path to mridangam left audio file
audio_mridangam_right_path (str): path to mridangam right audio file
audio_violin_path (str): path to violin audio file
audio_vocal_s_path (str): path to vocal s audio file
audio_vocal_pat (str): path to vocal pat audio file
ctonic_path (srt): path to ctonic annotation file
pitch_path (srt): path to pitch annotation file
pitch_vocal_path (srt): path to vocal pitch annotation file
tempo_path (srt): path to tempo annotation file
sama_path (srt): path to sama annotation file
sections_path (srt): path to sections annotation file
phrases_path (srt): path to phrases annotation file
metadata_path (srt): path to metadata file
Cached Properties:
tonic (float): tonic annotation
pitch (F0Data): pitch annotation
pitch_vocal (F0Data): vocal pitch annotation
tempo (dict): tempo annotations
sama (BeatData): sama section annotations
sections (SectionData): track section annotations
phrases (SectionData): phrase annotations
metadata (dict): track metadata with the following fields:
- title (str): Title of the piece in the track
- mbid (str): MusicBrainz ID of the track
- album_artists (list, dicts): list of dicts containing the album artists present in the track and its mbid
- artists (list, dicts): list of dicts containing information of the featuring artists in the track
- raaga (list, dict): list of dicts containing information about the raagas present in the track
- form (list, dict): list of dicts containing information about the forms present in the track
- work (list, dicts): list of dicts containing the work present in the piece, and its mbid
- taala (list, dicts): list of dicts containing the talas present in the track and its uuid
- concert (list, dicts): list of dicts containing the concert where the track is present and its mbid
----------------------------------------------------------------------------------------------------
Dataset loaders provide a vast amount of advantages and introducing these into our research pipelines may be very beneficial. compiam relies on mirdata, a Python library focused on common dataloader for MIR datasets. So bear in mind that when loading a particular dataset using compiam.load_dataset(), we are basically initializing a mirdata dataloader. To get a more insightful walkthrough of the dataset loaders and how these work, please see Datasets, and make sure to check out and star mirdata.
The .load_corpora() wrapper#
compiam provides access to both Carnatic and Hindustani [SKG+14] corpora from Dunya. Initialize the access tool to these huge collections of data using the designated wrapper.
## Initializing dataloader for an example dataset
carnatic_corpora = load_corpora("carnatic", cc=True, token="your-token-goes-here")
Warning
A complete walkthrough of the corpora access in this book is not possible because of the explicit need of a unique, personal, and intransferible access token. Please get your token and check the detailed documentation we have put together. Feel free to reach out in case you encouter issues or questions.
The .load_model() wrapper#
For the case of ML/DL models that are data-driven and therefore trained using particular collections of data, we may use the compiam.load_model() wrapper to load the tool as you would do using from compiam.<musical-aspect>.<task> import <particular-model>. However, loading the model using the wrapper will load by default the pre-trained model given publicly available weights and checkpoints for the integrated implementation.
Tip
When listing available tools using the list_tools() functions, some will appear with a * at the end. That is meant to indicate that such tools have pre-trained models available, which may be loaded using the wrapper compiam.load_model().
You may obviously initialize the untrained version of the model and load the weights afterwards, especially if you have your own checkpoints or seek to train the model yourself. However, the compiam.load_model() wrappers offers a handy and rapid way to load a pre-trained model for a particular task. The weights for the integrated models are NOT included in the release of compiam (given the extensive size), but when models are loaded with the wrapper, the weights are automatically downloaded from the cloud and stored in compiam/models/<musical-aspect>/<model-name>/ (writing the path UNIX-styled here!). You can set up the download path using the data_home argument of the wrapper (leveraging the naming convention from the mirdata library).
Important
Only the ML and DL-based models with available weights can be loaded using the .load_model() wrapper. The non-trainable tools or the models with no available weights must be imported from their corresponding module.
Let’s list the available pre-trained ML/DL models through compiam.
pprint(compiam.list_models())
['melody:deepsrgm',
'melody:ftanet-carnatic',
'melody:ftaresnet-carnatic-violin',
'melody:cae-carnatic',
'structure:dhrupad-bandish-segmentation',
'separation:cold-diff-sep',
'separation:mixer-model']
This list includes all the models in compiam that can be loaded using a set of publicly available weights. Let’s now run a snippet to show how fast we can expriment through the use of the wrappers in compiam.
%pip install "tensorflow==2.15.0" "keras<3"
Note
Some tools require specific dependencies that are not installed by default. These dependencies are specified in the online compiam documentation. In addition, if a tool is loaded and a dependency is missing, an error message will be thrown requesting the user to install the missing package.
# Loading pre-trained model for prediction
ftanet_carnatic = load_model("melody:ftanet-carnatic")
saraga_carnatic = load_dataset(
"saraga_carnatic",
data_home=os.path.join("..", "audio", "mir_datasets"),
)
These methods in the following cell download the dataser for you, and make sure no files are missing or have been corrupted during the downloading/unzipping process.
#saraga_carnatic.download()
#saraga_carnatic.validate()
Note
Saraga Carnatic is about 24GB of data and therefore we will not download it within the context of this tutorial.
An audio example from the dataset has been selected for tutoring purposes: “Sri Raghuvara Sugunaalaya” performed by Sanjay Subrahmanyan. The id of this track in the Saraga Carnatic dataloader is "109_Sri_Raghuvara_Sugunaalaya".
# Getting audio from random track in the dataset
saraga_tracks = saraga_carnatic.load_tracks()
our_track = saraga_tracks["109_Sri_Raghuvara_Sugunaalaya"]
# Predict!
predicted_pitch = ftanet_carnatic.predict(our_track.audio_path, out_step=0.005)
.predict() here includes a parameter to control the timestep used to represent the pitch, which can help aligning the predicted pitch with the audio. Carnatic melodies can be highly oscilatory and jump spuriously, so we might need to use a smaller step size to better capture all detail. However, we may not use an extremely small step size, which may lead to unstable pitch representations and occupy a lot of memory.
Util functions#
compiam also includes visualisation and general util functions to assist the comprehensive computational study of musical repertoires and issue quite a number of operations that are useful for the said research field. Check the visualisation documentation and the utils documentation out for a detailed presentation of the available tools.
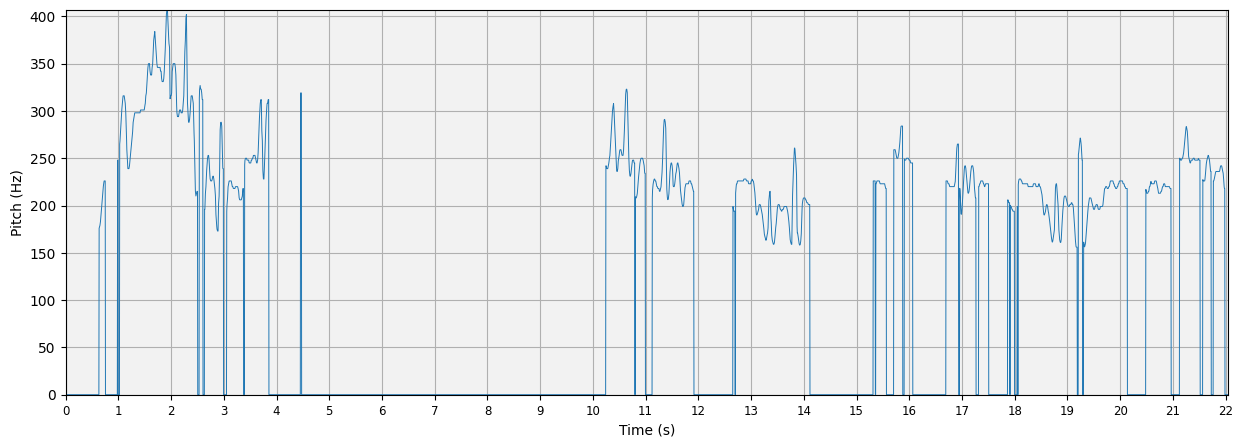
We will now use the .plot_pitch() method which allows us to plot the pitch curve we have just extracted from the audio example.
segment_in_seconds = 20
from compiam.visualisation.pitch import plot_pitch
# Getting audio and sampling rate
audio, sr = our_track.audio
# Plotting waveform
pitch_frames = int(segment_in_seconds * sr * 0.005)
plot_pitch(
pitch=predicted_pitch[:pitch_frames, 1],
times=predicted_pitch[:pitch_frames, 0],
);
# Playing 20 seconds of the audio used for prediction
audio_samples = int(segment_in_seconds * sr)
audio_short = audio[:, :audio_samples]
ipd.Audio(
data=audio_short,
rate=sr
)
The extent of compiam#
In the current latest version of compiam (v0.4.1), the package includes access to 10 datasets, access to the Carnatic and the Hindustani corpora in Dunya, and more that 12 tools and models to use, covering 9 different tasks. We are aware, and we are very interested in bringing that into the open, that the topic of the computational analysis of Indian Art Music, especially on the tools and models side, is way broader. The literature includes a vast amount of very interesting and relevant works that, mainly because of the time constraint, are not included in the first release of compiam.
However, we have been designing compiam so that it evolves as a community-driven initiative, in which anyone can integrate datasts, tools, and models for the computational analysis of Indian Art Music.
Therefore, this tutorial is also a great chance to present the official launch of compiam, and engage researchers and developers interested in the research topic of computational analysis of Carnatic and Hindustani music to contribute to this library. The ultimate goal of this software is that the relevant collections of data and versatile tools for this topic are made available an easy accessible for everyone, while boosting the visibility and community usage of these.
Contributing#
compiam is continuously evolving and it is very much open to contributions! We have put together complete set of contribution guidelines to help you improving and/or expanding the library. Potential contributions are:
Adding new implementations of tools or models.
Adding new datasets by first adding a dataloader to
mirdata(see Datasets) and then link it tocompiam(we do havemirdatamaintainers in the team therefore close help should be given).Fix, improve, update, or expand existing implementations.
Fixing bugs.
Improving documentation.
Don’t hestitate to reach out or open an issue in the compaim GitHub repository to request for further help or raise questions.